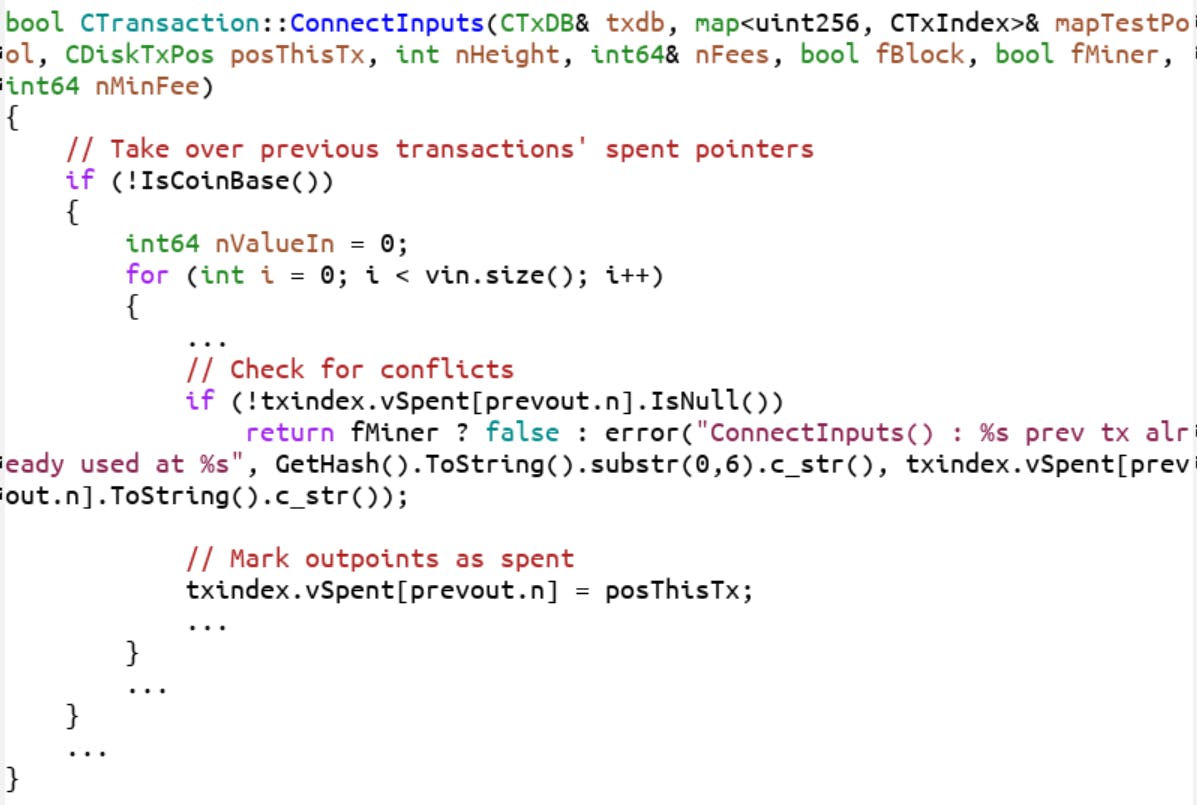
The Bitcoin world was surprised when last week, to the public and everyone was urged to upgrade as soon as possible. The ostensible reason was that there was a Denial of Service (DoS) vector found in 0.14-0.16.2 that needed patching. , we found out that there was the possibility of inflation due to the same bug in 0.15-0.16.2. 0.16.3 was released Later on In this article, I seek to clarify what happened, what the danger was, how it was exploitable and what could have happened. Two Ways to Double-Spend Before we get to the actual bug, some explanation is necessary. We need to define double-spending first as the bug was with double-spending. Double spending is the case where someone, say Alice, spends coins to Bob and the same coins to Charlie. Alice is essentially trying to write two checks, one of which she knows will bounce. Of course, when we’re thinking in checks, there’s some account that Alice has that’s getting overdrawn by writing these two checks. That’s close, but not quite exact in how Bitcoin works. Bitcoin doesn’t work on accounts but with UTXOs, or unspent transaction outputs. The outputs of a transaction have essentially an address and an amount. Once that output has been spent, it cannot be spent again. Think of a UTXO as a single coin that’s been sent to you that can be any amount, say, a 0.413 BTC coin. Double spending means that a single coin (UTXO) is being spent twice. Usually, this means Alice is sending her 0.413 BTC to Bob in one transaction and to Charlie in another transaction. The way this is resolved in Bitcoin is that one of those transactions makes it into a block and that determines who actually gets paid. If both transactions somehow come through in a multiple blocks, the latter block is rejected by the software. If both transactions come through in a single block, that block is also rejected by the software. Essentially, the software detects double-spending and if there is double-spending a block should be rejected. Sending the same UTXO in two different transactions is not the only way to double-spend, however. There’s a more pathological case of the same UTXO being spent twice . In this case, Alice is sending a single coin twice to Bob. So Alice is spending 0.413 BTC coin twice to send 0.826 BTC to Bob. This is clearly not a valid transaction as there’s only 1 UTXO worth 0.413 BTC being sent. This would be the equivalent of Alice paying Bob the same $10 bill twice and Bob thinking that he received $20. in the same transaction Defining the Bug So to sum up what we’ve defined so far, there are two types of double-spending attempts: Using two or more transactions to spend the same UTXO. Using one transaction to spend the same UTXO multiple times. It turns out that (1) is handled correctly by the Bitcoin Core software. It is (2) that’s of concern to us here. Anyone can construct a transaction that double-spends like this, but getting nodes to accept this kind of transaction is another matter. There are two ways to get a transaction into a block. A. Broadcast the transaction onto the network with sufficient fees to get a miner to include the transaction in a block. B. Include the transaction in a block as a miner. (A) doesn’t require much other than creating the transaction and broadcasting it to a node on the network. (B) requires that you find a sufficient proof-of-work. It turns out that for the bug, (A) is not a possible attack vector as those transactions are immediately marked as invalid and rejected by nodes on the network. There’s no way for the transaction to get into the mempool of miners without miners’ cooperation as they won’t get propagated. (B) is the only case in which the bug manifests. In other words, to exploit this bug, you need proof-of-work, or sufficient mining equipment and electricity. To be clear, there are 4 cases that need to be handled for double-spending: 1A — Multiple mempool transactions spending the same UTXO 1B — Multiple block transactions spending the same UTXO 2A — Single mempool transaction spending the same UTXO multiple times 2B — Single block transaction spending the same UTXO multiple times The bug has two manifestations. In 0.14.x, there’s a Denial of Service vulnerability and in 0.15.x to 0.16.2, there’s an inflation bug. We turn to those next. Denial of Service Vulnerability The story starts in 2009 with Bitcoin 0.1, where this bit of code enforces consensus by rejecting cases 1B and 2B (checking that blocks don’t double-spend): You can see the comment “Check for conflicts” which checks to see that every input is not spent yet. The code below the comment “Mark outpoints as spent” marks the UTXO as spent. If any UTXO is spent more than once, this causes an error. In 2011, was merged. This change was meant to take care of case the case where a single-tx double spend was being transmitted via the mempool (Case 2A above). This Pull Request comment makes the purpose clear (emphasis mine): PR 443 Also, no transactions with duplicate inputs get put in blocks…someone tried it a couple weeks ago, but the txes never ended up in blocks. Im assuming there is a check somewhere later on that prevented them from getting added to a block, though I haven’t done any digging on the matter. This is really to prevent such obviously invalid transactions from getting relayed. The actual code change more or less does the same thing as the code under the comments “Check for conflicts” in above, but in a different place. The code change is in , which is run for all 4 cases above (1A, 1B, 2A, 2B). As a result, we now have some redundancy in the block double-spending consensus code as Cases 1B and 2B are checked twice, once in and once in . ConnectInputs CheckTransaction CheckTransaction ConnectInputs In 2013, was merged. The goal of this change was to distinguish between consensus errors (like double spending) and system errors (like running out of disk space) as this PR comment makes clear: (emphasis mine) PR 2224 It introduces CValidationState, which stores metadata about a block or transaction validation being performed. Additionally, CValidationState also takes over the role of tracking DoS levels (so it doesn’t need to be stored inside transactions or blocks…). It is used to distinguish validation errors (failure to meet network rules, for example) with runtime errors (like out of disk space), as formerly these could be confused, leading to blocks being marked invalid because the disk space ran out. The actual relevant code change is here: By this time, had been modularized into multiple methods and this function became the one checking for double-spending. The key change here is that what was once an was changed to an . ConnectInputs error assert What does an do in C++? It halts the program entirely. Why would a programmer want to halt the program here? Well, this is where the purpose of the Pull Request comes in. Here is the relevant snippet of code from that time. assert This is handling Case 1B and 2B as before. The function name has changed from to , but the redundancy in checking Cases 1B and 2B have remained from PR 443. As we already saw, does the second double-spend check. does the first double-spend check by calling : ConnectInputs ConnectBlock UpdateCoins CheckBlock CheckTransaction Since this is the second time checking the same thing, the only way for the double-spend check in to fail is if there’s some sort of UTXO database or memory corruption. Indeed that seems to be the reason for the change to an . We already know the transactions aren’t double-spending as via does that check before . Thus, PR 2224 correctly surmised that getting to this state in must be a system error, not a consensus error. In that case, to prevent further data corruption, the correct thing to do is to halt the program. UpdateCoins assert CheckBlock CheckTransaction UpdateCoins UpdateCoins In 2017, was introduced as part of Bitcoin 0.14. As Segwit was going to make blocks larger, this was one of many changes to speed up the block validation times. The code change was pretty small: PR 9049 You can see here that the boolean was added to speed up Block checking. This was believed to be a redundant check as we’ll see below. Unfortunately, the code in was changed in PR 2224 to a and not meant to be a consensus check. By 0.14.0, the code had modularized more and the looks a little different: fCheckDuplicateInputs UpdateCoins system corruption check assert What was once a redundant check was now responsible for a block-level single-tx double-spend (Case 2B) and halts the program. This still technically enforces consensus rules, just very badly, by halting the program. How did PR 9049 get through? Greg Maxwell referred me to on IRC: this chat Major props to Greg Maxwell who helped spell out for me what happened TL;DR, the developers, when discussing PR 9049, were predisposed to think that a block-level single-tx double-spend (case 2B) was being checked elsewhere from PR 443 without taking PR 2224 into account. This caused the developers to not look as closely at PR 9049. To sum up: PR 443 was introduced in 2011 to prevent relay of double-spending transactions (Case 2A). This had a side effect of creating a redundant check of consensus rules for double spending in blocks (Cases 1B and 2B). PR 2224 was introduced in 2013 and as a side effect, upgraded the code in (1) for block validation from being redundant to consensus-critical. PR 9049 was introduced in 2017 and skipped over the code in (1) for the single-tx-double-spend-in-a-block case (Case 1B). The developers wrongly believed the code to be redundant because they didn’t take (2) into account. In actuality, this change skipped over a consensus critical part. It’s fair to say that this was a strange confluence of events that led to the bug. The Severity of the DoS Vulnerability This meant that Core 0.14.x software could crash given a weird enough block. Because of where the code is situated, to cause a crash, an attacker would have to: Create a transaction spending the same UTXO twice Include the transaction from (1) into a block with sufficient proof-of-work Broadcast that block to 0.14.x nodes (1) and (3) are not very costly. (2) costs at a minimum in 12.5 BTC as the amount of hash power required to create a block with sufficient proof-of-work requires the same amount of energy/mining equipment as finding a valid block. If you believe that splitting the network isn’t that great from a game theory perspective, the incentives to exploit this vulnerability are pretty low. At best, as an attacker, you take down a narrow slice of full nodes for the cost of 12.5 BTC. With the unlikely prospect of profiting off of a split network, which requires a lot more than just being able to crash some of the nodes at will, there’s not much to gain as the attacker cannot easily recoup the cost of the attack. If this were the only vulnerability, the attacker can inconvenience a lot of people, but it’s not a sustained inconvenience since those nodes can simply reboot and connect to nodes other than the ones feeding them the bad block. Once there’s a longer chain, this bad block attack would completely lose its teeth. Unless the attacker continues to create blocks at a cost of 12.5 BTC per block and feeds them to 0.14.x nodes on the network, the attack would more or less end there. In other words, while the vulnerability is certainly there, the economic incentives for DoS were pretty low. Inflation Bug Starting at 0.15.0, there was a feature introduced to make looking up and storing UTXOs faster and that introduced the next iteration of the bug. Instead of crashing when a block with a single-transaction double-spend came in, the software saw the block as valid. This means a pathological transaction (same UTXO being spent multiple times in the same transaction or 2B above) which crashes 0.14 nodes were now seen as valid in 0.15 nodes, essentially creating BTC out of thin air. Here’s how that came about. Introduced in 0.15, encompasses a lot of things, but the main gist of it was that the way the UTXOs were stored changed to make them more efficient to look up. As a result, there were many changes, including one to the function from earlier: PR 10195 UpdateCoins Notice how the code around was taken out entirely. Noticing this, , also in 0.15.0 changed the code so that the assert was put back. assert(false) PR 10537 The conditions under which the assert fails now depends on which looks like this: inputs.SpendCoin Essentially, the only way for to return false is if the coin doesn’t exist in the UTXO set. But as you can see that requires the coins to be and not . These are not obvious terms, but thankfully, core developer Andrew Chow explains : SpendCoin FRESH DIRTY here So now the question is, when are UTXOs marked as ? They are marked when they are added to the UTXO database. But the UTXO database is still only in memory (as a cache). When it is saved to disk, the entries in memory are then no longer marked as . This saving to disk happens after every block (as well as at other times, but that is not important). FRESH FRESH FRESH coins are ones that entered the memory pool. An attacking miner can crash the nodes through that assert statement in . But worse, if the coins are (essentially read from disk), then this can cause inflation. FRESH UpdateCoins DIRTY It’s thus possible to trick core software from 0.15.0 to 0.16.2 to accepting a weird, invalid block that inflates the supply. The Severity of the Inflation Vulnerability The economics of this attack seem significantly better than the Denial of Service case as the attacker could potentially create BTC out of thin air. You still need mining equipment to execute the attack, but the potential for inflation might make this worthwhile, or so it seems. Here’s what the naive attack on Bitcoin using this bug would look like: Create a block with a transaction that spends some amount of BTC back to yourself twice. Say 50 BTC →100 BTC. Broadcast the block to everyone on 0.15/0.16 Here’s what would have happened: 0.14.x nodes would have crashed Older nodes and many alternative clients would have rejected that block Many block explorers run on custom software and not core, so at least some would have rejected the block and wouldn’t have shown any transactions from that block Depending on the software miners were running we may have ended up with a chain split. It’s possible all miners were running Bitcoin Core 0.15+ in which case non-vulnerable clients would have simply stalled. It’s also possible a miner would have been running something else in which case a chain fork would have happened as soon as they found a block. Because of these irregularities, people on the network would soon have tracked this down, probably have alerted some developers and the core developers would have fixed it. If there was a fork, the social consensus at that point about which is the right chain would start getting discussed and the chain creating unexpected inflation would have likely lost out. If there was a stall, there likely would have been a voluntary rollback to punish the attacker. So for the attacker, this wouldn’t have resulted in +50 BTC, but much more likely -12.5 BTC. If the attacker double spent a bigger amount, say 200 BTC, there would be even less chance that the inflation block would stick around as the attack would be much more blatant. So from an attacker’s perspective, this wouldn’t be a very good return on investment. The other way that an attacker could have profited is by shorting BTC and then executing an attack. This, too, is risky because it’s not guaranteed that BTC price would go down, especially if the crisis was handled swiftly and decisively. Furthermore, given the AML/KYC around most exchanges offering margin, this likely results in the attacker getting doxxed in fairly short order. Not only does an attacker have a significant amount of monetary risk, but also physical risk. The ROI isn’t really there and from an economic perspective, this is not an easy exploit to profit off of. A state-level actor, however, could have used this as a way to scare Bitcoiners. The ROI would be more abstract, so in theory, this could have accomplished the purposes of a state-level actor. Conclusion For sure, this was a pretty severe bug. And despite my differences with , I’m grateful that this person chose to disclose responsibly. That said, given the economic game theory of the exploits, I don’t believe the bug was nearly as severe as people like him have made it out to be. Awemany Even if the bug was made known to bad people before it was found, it’s likely that this wouldn’t be something an attacker would choose to exploit as the economics don’t really make sense. To be sure, the technical part should be fixed and made better, but the group of people that this exploit would actually be useful to is really tiny (state-level actors who want to try to destroy Bitcoin, basically). The lessons for Bitcoin Core are many: Any consensus changes (even tiny ones like 9049) need to be reviewed by more people. More tests for pathological cases need to be written. More clarity in the codebase about which checks are redundant and which ones are not and what the actual code is meant to be doing. There have been bugs in the past, there will be bugs in the future. What’s important now is to learn and incorporate these lessons.