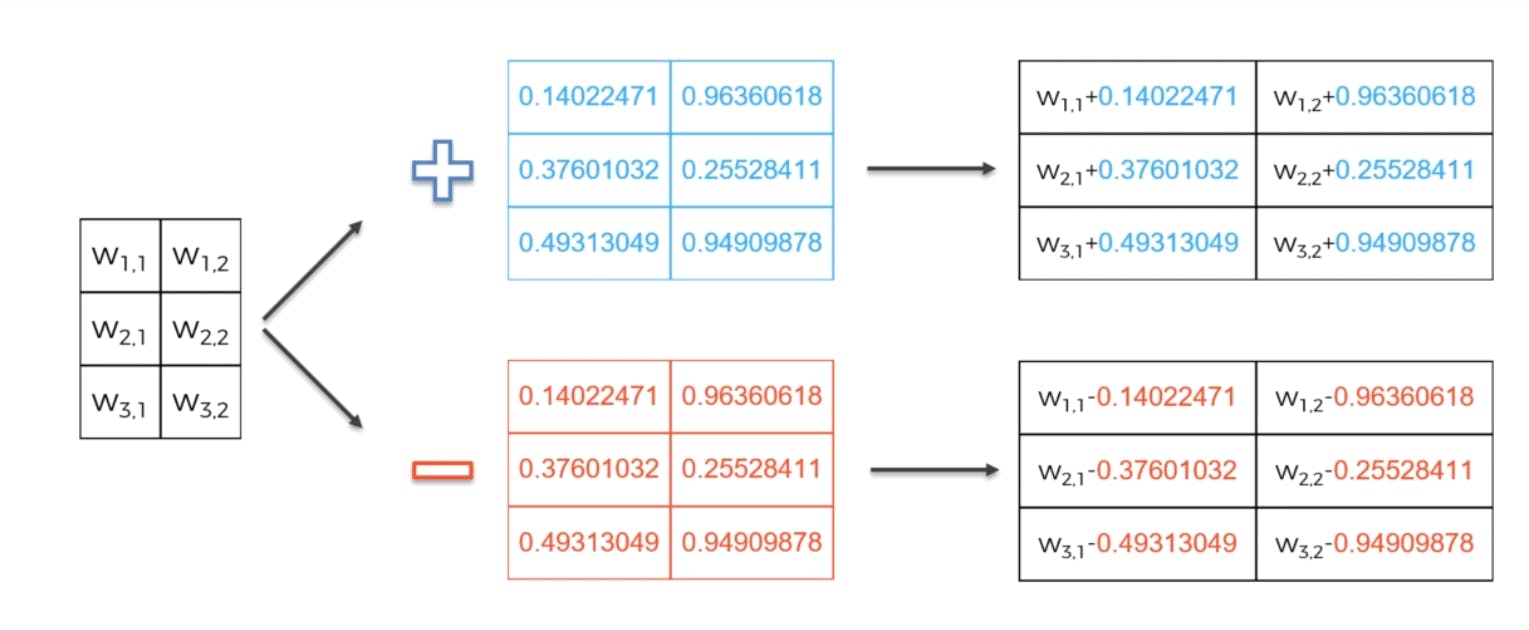
Augmented Random Search is truly one of the most mindblowing I’ve come across with my research in reinforcement learning. algorithms Augmented Random Search(ARS) is actually up to than other algorithms with higher rewards in specific applications! That’s insane! 15 TIMES FASTER One of the ways, ARS is able to be so much faster is that unlike a lot of reinforcement learning algorithms that use deep learning with many hidden layers, augmented random search uses perceptrons! There are fewer weights to adjust and learn, but at the same time, ARS manages to get higher rewards in specific applications! So, higher rewards AND faster training time! Using ARS I was super curious about the results on a project so I decided to train a half cheetah to walk using ARS. Here’s the final result of the AI learning to walk! We get rewards for each configuration of weights from the environment and some are higher than others. What ARS does it that it . The higher the reward, the more the weights were adjusted, the lower the reward, the lesser the weights were adjusted. adjusts those weights according to the weight configurations that it gave the best rewards This is the equation that helps calculate this. This picture shows 4 different weight configurations with the coefficient being the difference between the positive configuration of that weight and the negative configuration of that weight. The greater the difference between the rewards, or in other words, the better the reward, the bigger the coefficient will be for that specific configuration of weights, meaning it will influence the weights more. One of the additional modifications to the above equation is that the researchers discarded low rewards immediately. They only used the top k configurations with the highest reward. Intuitively this makes sense because why would we keep pursuing and experimenting with weights that give a low reward? By taking them out, we save time and computational power! ARS also does things a little bit differently than other algorithms by exploring policy spaces instead of action spaces. Basically, this means that to determine if that set of actions led to a higher reward. instead of analyzing the rewards it gets after each action, it analyzes the reward after a series of actions To sum up the main ideas: ARS uses a perceptron instead of a deep neural network. ARS randomly adds tiny values to the weights along with the negative of that value to figure out if they help the agent get a bigger reward. The bigger the reward from a specific weight configuration, the bigger its influence on the adjustment of the weights. All in all, this is an incredible reinforcement learning algorithm and the results are amazing! The Code & The Demo This code above here is super important because this is where the equation I showed above is implemented! This is how the weights are updated according to which configuration of weights led to the biggest reward! This part here shows how the positive and negative configurations of the weights are both used in episodes to figure out whether they give a higher reward. The only difference in the two pieces of code is that one points to an equation with a plus sign for the positive configuration and the other points to an equation with a subtraction sign for the negative configuration. Let’s take a look at some of the training videos now! So at first, you can see that the agent barely lasts for a couple seconds before falling and the episode ends. A little bit later on, it’s able to balance, but it doesn’t understand quite how to walk using legs. Finally nearing the end of the training, the agent understands how to balance and use legs to push itself forward. Although these were short peeks into what the agent was doing, you can clearly see the progress from not being able to balance, to not moving, to finally balancing and moving to walk! It’s things like this that make me so excited about reinforcement learning. It’s still early days for the fields. We can train agents to play games, get them to move like humans, and even understand organic chemistry to generate new drugs! As exponential technology progresses and more and more people start working on them, I can’t even begin to imagine some of the unique applications we’ll be able to come up with! Before you go: 1. Clap this post. 2. Share with your network! 3. Connect with me on linkedin ! 4. Check out my website: www.anishphadnis.com