33,032 reads
Audio Handling Basics: Process Audio Files In Command-Line or Python







EN

Too Long; Didn't Read
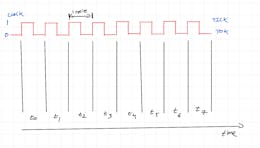
Audio Handling Basics: Process Audio Files In Command-Line or Python. This article shows the basics of handling audio data using command-line tools. It also provides a not-so-deep dive into handling sounds in Python. The two basic attributes of sound are amplitude (what we also call loudness) and frequency (a measure of the wave’s vibrations per time unit) We use the sampling frequency (fs = 1/Ts) as the attribute that describes the sampling process.Company Mentioned






Theodoros Giannakopoulos
@tyiannak
I make algorithms that understand sounds
About @tyiannak
LEARN MORE ABOUT @TYIANNAK'S
EXPERTISE AND PLACE ON THE INTERNET.
EXPERTISE AND PLACE ON THE INTERNET.

L O A D I N G
. . . comments & more!
. . . comments & more!