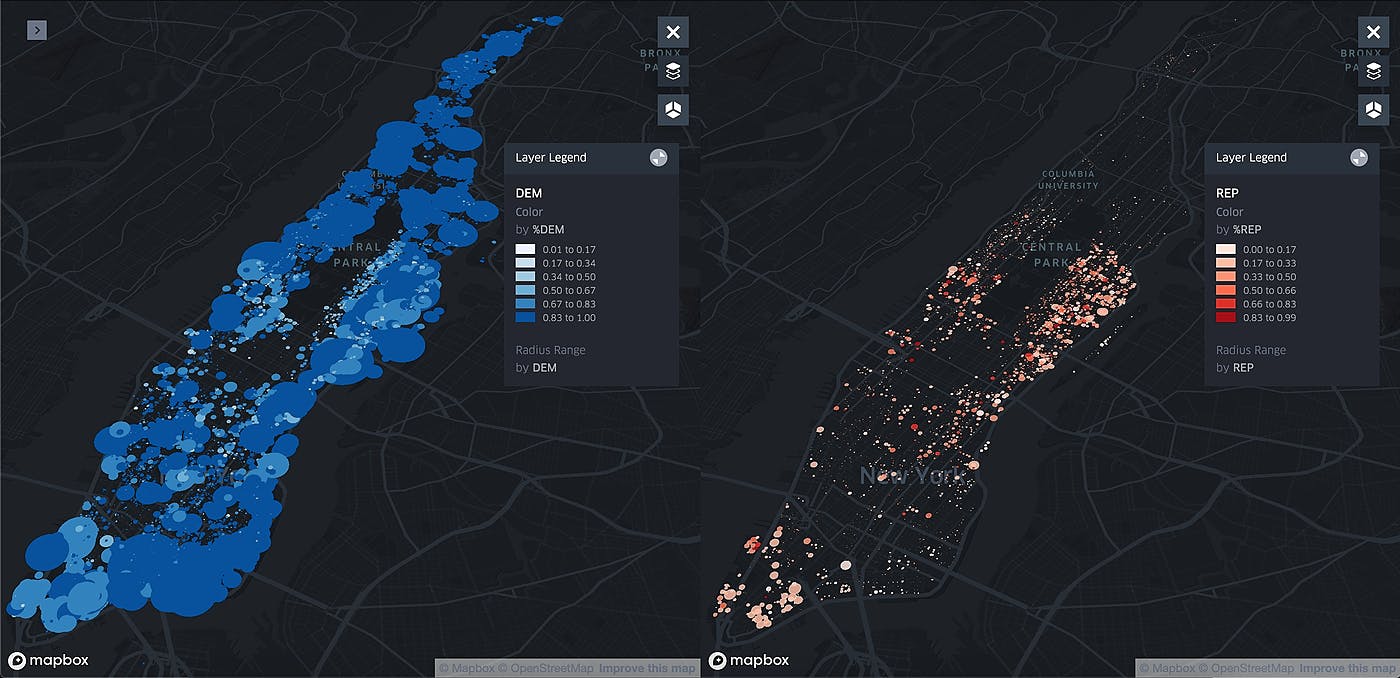
What if you could instantly visualize the political affiliation of an entire city, down to every single apartment and human registered to vote? Somewhat surprisingly, the City of New York made this a reality in early 2019, when the NYC Board of Elections decided to release . These records included full name, home address, political affiliation, and whether you have registered in the past 2 years. The reason according to this was: 4.6 million voter records online, as reported by the New York Times article Board officials said their print vendor was not able to produce enough copies of the voter enrollment book in time for candidates to begin gathering petition signatures in February, which is why they posted the information online. so this became the ‘stopgap’ in the meantime. Although as NYC BOE spokeswoman Valerie Vazquez-Diaz said in the same article: Whether you were aware of it or not, NY voter data is public record. While the idea of a city making 4.6 million personal records of voters publicly available on a whim is deeply troubling, and I plan to discuss that in another article, the opportunity to visualize this data intrigued me. With most public datasets, the most granular you tend to have access to is maybe level, but New York City just laid out one of the most unique datasets in the world! For the first time there now existed a dataset to visualize a vast array of hyper-granular voter data, including political affiliation concentration by area, whether there are concerted efforts in certain areas to register new voters, and how dominant parties are at a scale that people can understand. census tract In the end I decided to attempt and publish this for two reasons: 1. Public officials need to better consider the potential ramifications of posting a massive dataset like this online In this case it took a single, semi-technical person a few weekends of their free time to download, transform, and search through millions of records. Not only did I do that, but I was able to geocode over a million records for about $30 after credits on Google. Privacy needs to be top of mind as opposed to an afterthought in this digital age. 2. At an aggregated level this data offers new and unique insights that are valuable to a broad spectrum of people I do believe this dataset (visualized/analyzed at the building-level) can offer unique insights while maintaining the privacy of myself and other New York residents. In aggregate, I found that there does indeed exist concentrated areas that are party-dominant, and that party dominant clusters occur across the entire city. I also found that new voter registration were highly concentrated in areas like Alphabet City and the Upper East Side, with some clusters having up to 5x higher registrants vs. others. The remainder of the article will cover the methodology of transforming ~600 PDFs into a usable dataset, three visualizations of unique comparisons observed, and a conclusion with suggestions on further research. Methodology Now just because data is available doesn’t mean it’s accessible, which was demonstrated by the way the data released. Let’s take a redacted look at the raw PDF below: From a data science perspective, this is an absolute nightmare. A few of the many reasons: It is displayed as three ‘tables’ per page in a PDF, so excel/other programs do not consume it as you would expect. It more or less explodes and generates random entries in random cells, so no-go for simple copy/paste Data overlaps (street name overlaps with names) so there no easy way to delimit columns Data points like street number are initially stated only once Columns/new pages can start with no data (ex/ no street number on the 2nd column) so there needs to be a way to remember ‘most recent’ elements It only has addresses, and you need latitude/longitude data in order to visualize on a map Since I’m a Python person, I immediately began trying to use the various existing libraries like to try and read the data, but it became clear that the formatting of the PDF would not allow for this. Troubled after sinking my first few hours into a dead-end, I began to re-think my strategy. If I couldn’t use the existing way the data was structured on the page, I needed to find a way to completely isolate and rebuild every word from the ground up on the page. PyPDF2 Enter Optical Character Recognition (‘OCR’). Using the library, I changed my strategy by telling my program each page was an image instead of a PDF page. In fact, all it takes is a single line of code: Pytesseract text = pytesseract.image_to_data(page) To give you coordinates for virtually every element on the page: Once I was able to confirm this, it’s a matter of working out how to use those positions in order to construct a custom delimiter to loop through each page. Unfortunately most of the first few columns wouldn’t work due to the way Pytesseract chose to group things, but the info for ‘left’, ‘top’, ‘width’, and ‘height’ were accurate from what I could tell. So for my program, I basically utilized the following logic: Read page as an image Isolate data table on left side Use left/top positions to determine row/column groupings Make into a DataFrame with separate columns for street number, name, zip, etc. Perform above steps on middle then right data table Move to next page To be fair, there was of nuance and edge case handling I had to deal with, and the results of OCR are not perfect (which I’ll discuss more in the conclusion). However, after a day or two of tinkering around, I was able to successfully iterate through my first 250 page PDF in about 30 minutes and transform it into a fully utilizable data table! a lot Now was the fun part, how do I translate this onto an actual map? I had addresses, but I wouldn’t be able to actually map them unless I could somehow find the lat/lon coordinates for each address. When I looked at the unique Manhattan addresses I successfully converted, it came to almost 100,000 unique addresses, so doing this part manually was out of the question. Luckily, not only does Google have a Reverse Geocode API, but I found a fantastic python library called that let me easily create a function to geocode a list of addresses in under 20 lines of code. Geopy geopy.geocoders GoogleV3 time sleep geolocator = GoogleV3(api_key= ) lat,lon = [],[] i streets: attempt range( ): : location = geolocator.geocode(i) lat.append(location.latitude) lon.append(location.longitude) : : sleep( ) : print( .format(i)) lat.append( ) lon.append( ) sleep( ) from import from import "<your API key>" for in #streets = array of addresses for in 2 #try at least twice to get address try except continue else break 2 else 'attempts maxed for {}' '' '' 5 Since I had never used Google’s cloud platform, I started with a $300 free credit, which helped offset the total cost of ~$330. Emboldened by my free credits and whimsy, I let my program execute over the next ~12 hours to return a beautiful set of lat/lon coordinates for almost all the corresponding addresses. After joining that with the aggregated dataset and doing some data cleanup (see conclusion), it was time to determine how to visualize it. Visualizing massive datasets is no small task, outside of finding a visualization library that can handle several hundred thousand rows, you also need to consider the technique for visualizing the dataset so that the end result is meaningful and truthful to the underlying data. I initially began using a fantastic new project in the Machine Learning community called , but ultimately decided I didn’t want to create a dashboard since too much clutter detracted from the focus (mapping the data). Streamlit Ultimately I went with the graphing library made by the Uber Visualization team called . Kepler uses as the underlying map provider and does an amazing job not only at handling large datasets, but is extremely accessible even for people who don’t code. After experimenting with a few different techniques, filters, and layers designs I decided on the three most impactful below. Kepler.gl Mapbox Raw Dominance of Voters One of the first things I wanted to see was ‘ ’? I wanted to do this for two reasons: what does each party concentration look like in isolation To see if the data I pulled roughly approximates reported party dominance (Democrats have made up ~68% of the ) voting population To clearly identify concentration areas without one party dominating the map due to skew To do this I created a dual view of each party on a map, made the radius width based on the concentration of points in a given area (intensity of registered voters in area), then created a sequential quantized color scale based on the avg. percentage of buildings in the area the parties occupy. As we can see in the map comparisons Manhattan is indeed overwhelmingly Democratic, and many multiples more concentrated in areas like Harlem (northern piece of Manhattan). Not surprisingly they tend to also make up a majority of voters in most buildings, as you can see by the darker blue prevalent in the map. Looking at the Republican side, it is clear that in raw numbers they make up a minority, and in areas where they do have large clusters are typically still dominated by Democrats (shown by the light vs dark red). It does appear that areas in the Upper East like Lenox Hill, Turtle Bay, and Yorkville are highly concentrated when compared to other areas. There also appears to be smaller concentrations in areas like Lincoln Square and around the Financial District, albeit much more sparse. Blended Dominance of Voters So now that we’ve examined the raw party dominance let’s try to combine onto a single map. The idea here is to try and show dominant areas of party concentration, while also maintaining the relative scale of the population. In order to do this I created a grid-style layer that used the sum of party counts in 0.2km (~0.06 mile) radius. I would then create a color for each grid based on the party most frequent party found in the area. My assumption was that even though the Democratic party dominates Manhattan, there are probably bastions of Republican-dominant areas. Below is the result: As we can see, there are no surprises here as the Democratic party dominates the map, even in areas like the Upper East Side where Republicans were most concentrated. There does seem to be some thematic areas like the Southeast area of Central Park, but ultimately there’s very little dominance when compared at the same scale of Democratic concentration. New Voter Registrations One thing I was particularly curious about was whether voter registrations in Manhattan were concentrated in certain areas. The PDFs included data on voters that registered in 2017 and 2018, so I decided to see what insights could be gleaned. Overall, I was able to capture about 55,000 newly registered voters, so I decided to aggregate new voters in 0.2km (~0.12 mile) clusters. Manhattan itself is only about 2.3 miles wide, so it’s important to pick a scale that’s going to be meaningful to the area you are representing. At first I tried separating out the parties like the dual map above, but saw surprisingly little variety in areas new Democrats vs. Republicans were registering. I instead decided to combine new registrants from both parties together and look at 2017 vs. 2018 new voters in aggregate. As we can see, there are two areas where new voter registrations were very concentrated — the Lenox Hill/Yorkville area in the Upper East Side, the area around Alphabet City in the East Village. It’s difficult to glean any definitive insight from this, but the concentration is interesting since the red areas have almost 5x the concentration of new voters vs. the cooler green areas on the map. There’s a few ways to potentially interpret this — perhaps these areas are comprised of more new individuals relocating to Manhattan relative to other areas; or, it could be reflective of concentrated efforts by the community to encourage voter registration. Conclusion This was a really interesting project to tackle, but there’s a few disclaimers I also need to highlight about the analysis. First and foremost, using OCR like I did comes with a big trade-off in terms of accuracy. My final dataset was trimmed to about 750k aggregated records, much of which was due to data I had to throw about because the OCR read it incorrectly (ex/ ‘100 Orange Street’ may be read as ‘T0O 0range $treet’). Because data like street numbers and names appear only once in some cases, the program misreading them in this way ultimately causes the lat/lon coordinates to either not be found or incorrect. I used my best judgement in attempting to toss out clearly incorrect large concentrations of data, but just know that this dataset was not perfect and may not be 100% representative of the reality. Although the data is likely directionally accurate, I have no perfect verification method since it was a one-man operation. I would love to see cities think about how to create more open datasets like this. Although I’m disappointed in the way New York City released the dataset, I think the underlying data at an aggregated level offers huge value to many interested parties. Not only could this help researchers better understand voter trends, but could also greatly contribute to studies and related to issues such as and . Gerrymandering Redistricting Further research could incorporate blending in other datasets like US census data to understand things like voter engagement in areas, or socioeconomic mixes that spur voter registration. I also did not visualize areas like Brooklyn or other parties outside of Republicans or Democrats, so those are still unexplored territory as well. I’m sure that looking further into these areas would uncover more unique findings about the composition of New York voters. I hope this was helpful and gives everyone food for thought — thanks for taking the time to read through, and feel free to comment below with thoughts or questions!


















![What Are Convolution Neural Networks? [ELI5]](https://hackernoon.imgix.net/images/69s32rn.jpg?auto=format&fit=max&w=3840)








