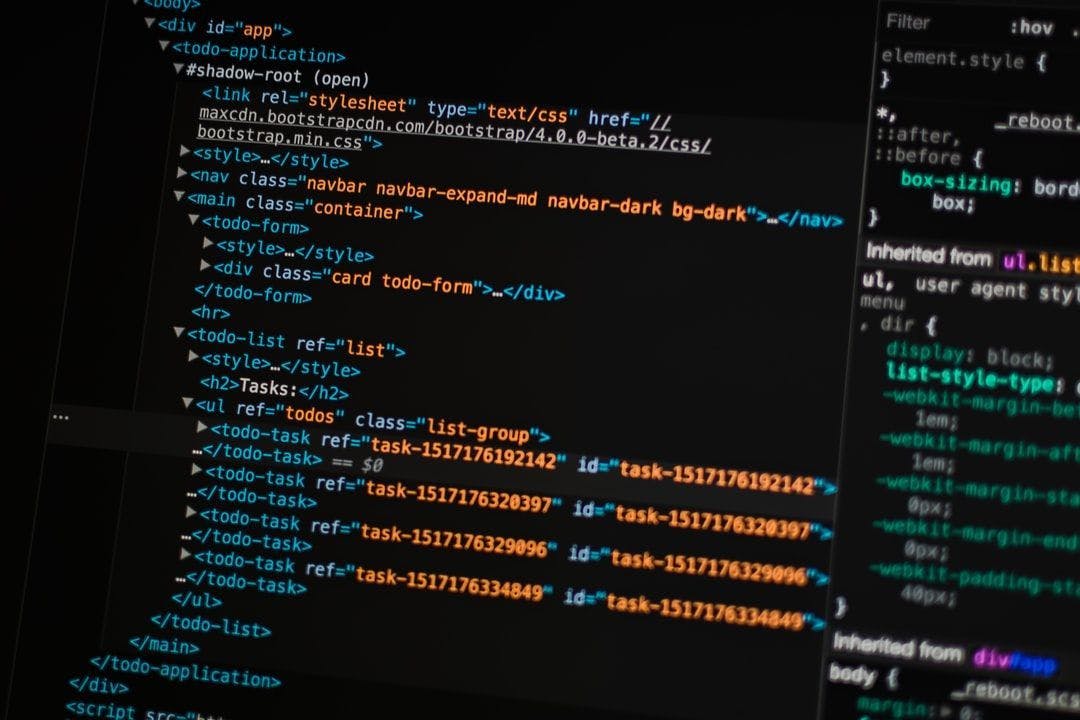
Internet is full of data. If you’re reading this you’re probably attempting or have attempted to collect it from some page. Maybe for a personal project, for a working project, whatever. You open the website, you see the data, you want to get it. Before I knew about web scraping and how to automate data collection, I had to give up on a few ideas because the cumbersome work of collecting thousands of data points manually was completely infeasible. In this article, we’ll see a quick introduction to web scraping, what it is, how it works, some pros and cons, and a few tools you can use to approach it so you do not have to watch your great idea die because you lack data. What is Web Scraping Web scraping is the process of collecting data from websites using automatized scripts. It’s used, of course, to gather large amounts of data that would be impossible to gather manually. It consists of three main steps: 1 — Fetch the page; 2 — Parse the HTML; 3 — Extract the information you need. The first two steps are not a problem. You just have to send a request to the website, get the response, and parse it. It’s usually done with a couple of lines of codes if you’re using code to scrape, for example, and most programming languages have libraries that are ready to help you with it. The third step is the one that can be a little tricky at first. It consists basically of finding the parts of the HTML that contain the information you want. You can find this info by opening the page you want to scrape and pressing the F12 key on your keyboard. Then you can select an element of the page to inspect. You can see this in the image below. With that done, all you need to do is to use the tags and classes in the HTML to inform the scraper where to find the information. You need to do this for every part of the page you want to scrape. Put like this, it may seem harder than it actually is, though. You do not need to master HTML to understand how to find an element as I did not know any of this when I started, for instance. Dealing with HTML is something you’ll get used to while learning to scrape and as much as the tool you're using requires you to. Pros and Cons of Web Scraping Speed, Flexibility, and Cost Web scraping is not only fast when compared to collecting data manually (actually, that comparison is not even fair at all), it is just fast. Depending on the data availability, a well-designed scrapper can collect dozens of thousands of data points in a matter of minutes. Also, when talking about speed, scrapers are not only fast to collect the data, they’re also fast to be built once you understand the tool you use. So that’s two advantages in one. Flexibility is my favorite pro of web scraping. This means It’s possible to collect virtually not only any data you need but as you need it and also store it how you want to. This means you can clean the data and create new features as you collect the data, avoiding the need for further treatment. And, of course, cost. You’ll not spend much to build a powerful scraper. In fact, until some point, you’ll spend nothing at all. Most tools for the job are open source and tutorials are all over the internet. Even if you need a more complex, non-open-source tool, chances are you won’t spend much, especially compared to the amount of data you’ll get. But it’s not all sunshine, so let’s talk about some cons as well. Learning, Maintenance, and Blocking First, you have to learn how to do it. This is not a big con, sure, you have to learn anything in life, but for people that are not familiarized with programming or with how the internet works, it can be a little harder at first. If you have to learn to code and then learn to scrape, the path will be much longer. It’s a point worth mentioning. But then you figure it out and build your scraper. It’s now running and tethering lots of data for you. Now you have to worry about maintenance. Constant maintenance. You know, websites change and you never know when. And the page you’re scraping change, one of the following will happen: 1 — The scraper will crash at some point because it won’t be able to find one or more elements; 2 — The scraper will collect wrong or inconsistent data, and this is even more critical since you’ll not notice it’s happening. So a web scraper is not something you build and just leave it alone. You need to pay constant attention to what is going on with it. Last but not least, you may get blocked. When scraping a page, the code is sending multiple requests to the website, and the website is able to identify these automated requests and block them if it gets tired of you. If that’s the case, it’ll be necessary to fall back on services and tools to disguise your scraper and overcome the issue. If the idea is to collect data directly from an API, this scenario of blocking can be even more dangerous to your operation. The owners of the API can, as suddenly as it is possible, decide to hide the endpoint and, just like that, your data source is over. The bottom line here is that it’s necessary to take constant care of the scraper, with constant monitoring and updates to make sure it keeps delivering the correct data it was designed to deliver. That will probably take time and money. Web Scraping Tools When choosing the tool for scraping, there is a major choice to be made: using a programming language and building everything on your own, using a web scraping no-code tool such as , or even hiring a web scraping service. Let’s understand more about these options. Octoparse Programming Languages There are multiple programming languages used for scraping, some of them are Java, Node.js, Ruby, and Python, which is the one I usually use. No matter which one you choose, if you’re not a programmer, you have to consider the learning process as a barrier. Although you’ll have zero cost at first as most of the tools are open source, the cons mentioned earlier will have much more impact on your project: maintenance will be more complex, and more tools will be necessary to avoid being blocked, for instance. No-Code By choosing a web scraping no-code tool the learning process is way more simple since no code would be necessary. Actually, using Octoparse, not even HTML knowledge will be demanded. Thus, the maintenance, although constant, becomes much simpler. The solution also counts with built-in solutions to problems as the ones mentioned above such as infrastructure of IP addresses to keep you from being blocked, and also other conveniences such as task scheduling, and easy connection to SQL and NoSQL databases, Dropbox, Google Sheets, Google Drive and more. Services Web scraping as a service is usually a better option for very large companies that consume huge chunks of data constantly and in short periods of time. If that's your scenario, then you might want to just receive all the data ready to be used, instead of going after it yourself, since the infrastructure you’ll need to build to deal with all this data may be more expensive than hiring a service the will delivery it to you. That’s the situation where you want to hire a company specialized in web scraping services to get the job done for you. It’s a completely different approach, but also worth mentioning. Wrapping Up As you can see, web scraping is full of possibilities and can be the solution for all sorts all problems when it comes to data acquisition. The most important is to have a good understanding of the problem you need to be solved, and the infrastructure, budget, and expertise available. With all that in mind, maybe all we’ve talked about in this article will help you make the best possible decision!