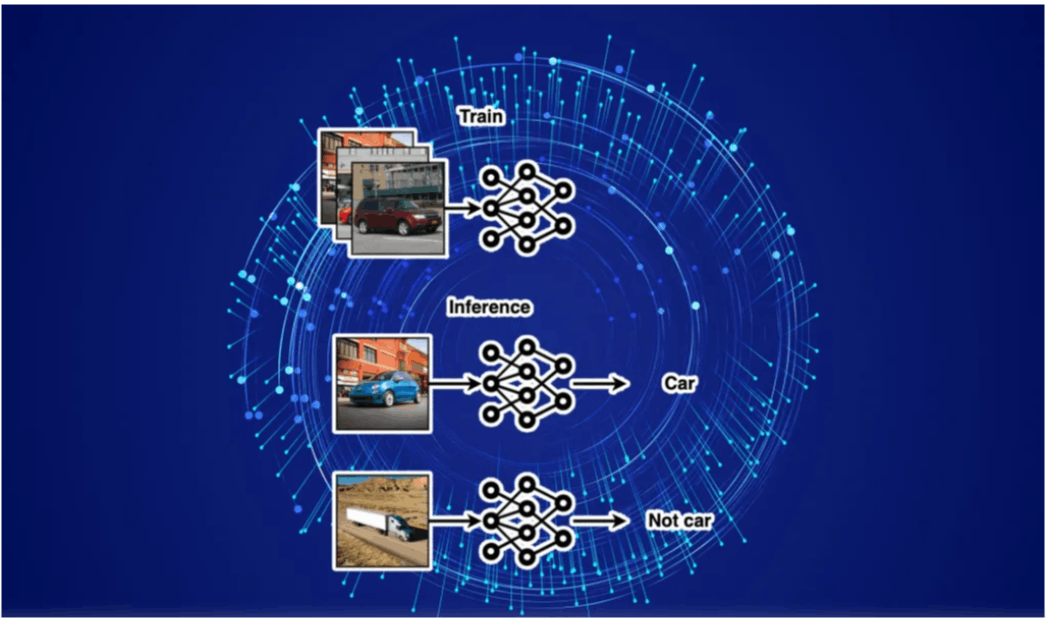
The emergence of (LLMs) has been nothing short of a technological marvel. These mammoth models, such as GPT, BERT, RoBERTa, and others, have reshaped our understanding of natural language processing and transformed industries ranging from healthcare to entertainment. Large Language Models Yet, for all their genius, LLMs have a fundamental limitation: they are general-purpose models, which makes them akin to versatile Swiss army knives. While they can handle a myriad of tasks with admirable competence, the true mastery lies in task-specific performance. This is where the concept of fine-tuning steps in, promising to unlock their full potential. In this exploration, we delve into the fascinating journey of fine-tuning LLMs for specialized tasks. We will explore the landscape of chatbots, language translation, and sentiment analysis, illuminating the nuanced process behind each adaptation. This journey aims to reveal not just the 'how' but also the 'why' of fine-tuning. The Art of Fine-Tuning resembles sculpting a raw block of marble into a masterpiece. It starts with selecting a base model — often a pre-trained LLM like GPT-3.5 from openAI, Falcon, LLAMA2, and Mistral from Hugging face transformers library — as the foundation. This base model has already been trained on vast swaths of text, saturating it with a deep understanding of language. Fine-tuning an LLM In the process of finetuning, it adapts to specific tasks through a process of focused training. Imagine, for instance, crafting a chatbot capable of realistic, context-aware conversations. Fine-tuning involves feeding the model with task-specific data and objectives, allowing it to refine its responses gradually. Let us then embark on a journey through three distinct applications of fine-tuning: Chatbots, where we'll unveil the strategies behind crafting chatbots that feel human; Language Translation, which would allow us to explore how LLMs can seamlessly switch between languages and dialects; and finally, with Sentiment Analysis, we'll delve into the mechanics of sentiment analysis and how fine-tuning refines it. As we unravel the art and science of fine-tuning LLMs for specialized tasks, it becomes clear that this process is the key to unlocking their full potential. It's not just about having a Swiss army knife, but more about sharpening each blade to perfection for a specific purpose. The Fine-Tuning Process Fine-tuning is a process where we start with pre-trained models as our initial foundation and then train these models with custom data to tweak some of the model parameters. This helps refine the model’s representations and weights, aligning them more closely with the requirements of the downstream task. In this chapter, we will explore the art of fine-tuning with transformers trainer which helps us in training these pre-trained models, and Optuna, a versatile hyperparameter search framework, for finding the parameters that will give the best performance on your downstream task. Let’s assume a text classification problem, the data consists of two features namely “text” and “labels”. Given the text, our task is to Since we are using the transformers library for training, we have to convert the data into format. classify it into one of the labels. ds.arrow_dataset.Dataset Once data is set up, load the tokenizer and foundation model for the downstream task. The above code imports a tokenizer for our language model. It takes either a Namespace from Huggingface repo like “bert-base-uncased” above or a path to the vocab files required by the tokenizer if you have saved any previously using the save_pretrained method, as input. Similarly, we import our initial model and it’s config using the above code. Now, our tokenizer, data, and the initial model have all been set up. It’s time to tokenize our data using a tokenizer since tokenized data is the input for model training and not the raw data. The above code tokenizes the training data. After tokenizing, we have to remove the text column since it is of no use from now on — we only use tokens. If you have the length of the sequence that is more than the accepted model’s sequence length, you must truncate; and if the max sequence length of custom data is less than the accepted model’s sequence length, then you can pad all the sequences with the padding parameter as shown above. This results in getting all the sequences with a constant length. Similar code can be used for tokenizing validation data and test data which we will use for evaluation and inference. Once training, validation, and test data have been set up, we need to create a function that helps in reporting metrics for every epoch. Let’s call it compute_metrics. The above function takes the predictions from the trainer and it calculates accuracy, recall, and precision for every epoch and it is shown in stdout. How Optuna works We create an Optuna study that corresponds to an optimization task, i.e. a set of trails. Optuna requires an objective function to quantify the performance of a model with specific hyperparameters. The main purpose of this function is to guide the hyperparameter optimization process. It optimizes by conducting trials, each representing a unique combination of hyperparameters. Each trial will have fixed hyperparameters, and these are passed to the objective function to calculate the objective. It aims to find the set of hyperparameters that minimizes or maximizes this objective function, depending on whether it represents a loss or a score/metric. Each trial information is logged in the study, and this information can be saved to a database or in local storage. You can convert it into a data frame as well. Best trial and best parameter values are also stored in the study. One can view them using study.best_trial. Now, let’s define our objective function. The first step is defining our hyperparameter space in a dictionary as is shown below: Since we are using a transformer trainer, we will use this dictionary to define training arguments. One can find the training arguments . Each hyperparameter has been defined in a specific range using Optuna’s trial object. here So, the next step is to set up the training and evaluation code: The above code takes the train data, validation data and the training arguments that we defined previously and initiates the training process when the execution reaches . Then evaluation is done with method. trainer.train() trainer.evaluate() We predict the results for test data and store them in the variable. Since we are concerned about “recall” in this particular case, let’s return to test recall from the objective. Since this is a metric, we have to maximize the objective function. test_results The next is creating the Optuna study and starting the hyperparameter optimization job: This will create a new Optuna study with the name . Since we are returning a metric from the objective function, our direction is to “maximize” the objective function. will trigger the hyper-parameter optimization process and once it’s completed, one can view the best trial and see the parameters that are performing well. hyperprameter_optimization_bert study.optimize() Applications of Fine-Tuned LLMs The expert-level Large Language Models (LLMs), trained on vast datasets and meticulously refined, exhibit a remarkable versatility that extends across multiple facets of Natural Language Understanding, Content Generation, Specialized Domains, and, crucially, Ethical Considerations. In the arena of , fine-tuned models have proven their mettle in diverse applications. Firstly, they stand out in sentiment analysis, decoding the nuanced emotional tones embedded in textual content with remarkable accuracy. Fine-tuned LLMs are indispensable tools when analyzing public sentiment toward a political event or product feedback for market research. Moreover, they are good in language translation and multilingual tasks, exceeding language barriers to facilitate global communication and collaboration. Natural Language Understanding becomes an art form when fine-tuned LLMs are employed. They possess the uncanny ability to generate creative content, whether it be generating compelling narratives, poetic verses, or even witty advertisements. Industries like advertising and marketing have embraced these models, utilizing their capacity to create persuasive and engaging content that resonates with audiences deeply emotionally. Content Generation In , fine-tuned LLMs have cut out a niche of their own. They undergo fine-tuning to serve as diagnostic tools in the medical field, offering assistance in early disease detection and patient care. Simultaneously, their abilities extend to legal document analysis, parsing through extensive legal texts with precision, speeding up the work of legal professionals while ensuring accuracy and compliance. Specialized Domains Real-world examples of enterprises using LLM-based AI search engines are , which has refined LLMs by using targeted fine-tuning with a specialized set of legal documents, which has boosted the pace of data collection and analysis and unveiled the information concealed within documents. LawGeex and , IN-D AI However, as we tread into the future, cannot be overlooked. It is imperative that we address concerns related to misuse and biases in these fine-tuned models, since the list of concerns is quite long: it might be misinformation, plagiarism, privacy concerns, security threats, and even dehumanization of communication. Ensuring transparency, fairness, and accountability in their deployment is thus paramount. The responsible use of LLMs must be guided by ethical principles to multiply their potential while minimizing unintended consequences. Ethical Considerations Challenges and Limitations Continuing the topic of ethical concerns, fine-tuning does not absolve models of biases inherent in the data; in fact, it can amplify them. A model trained on biased data can lead to contradictory results, raising ethical concerns. However, they are not the only thing that should be kept a close eye on. Although fine-tuning in itself involves feeding the model with task-specific data and objectives, one of the primary challenges in this process is still obtaining this very data. High-quality, labeled datasets are crucial for training models to achieve peak performance in specialized tasks. However, many domains lack the necessary volume of data or represent niche topics where data collection is exhausting. This scarcity restricts the model's ability to generalize well to real-world scenarios. Another concern is overfitting. When a model is fine-tuned on limited data, it might perform exceptionally well on that specific data but fail to generalize to unseen examples. Overfitting is particularly problematic with LLMs due to their capacity to memorize vast amounts of information. Other than that, fine-tuning LLMs demands considerable computational power. Training large models on specific tasks not only requires specialized hardware but also results in significant energy consumption and costs. For researchers and organizations with limited resources, this poses a barrier to achieving the full potential of LLMs. As one ventures deeper into the age of AI, the precision offered by fine-tuned LLMs could bring a true revolution to the industries, from healthcare diagnostics to bespoke content creation. Yet, with great promise comes the imperative to navigate the nuanced complexities involved, ensuring both efficiency and ethical integrity. By acknowledging these challenges, the community can work collaboratively to develop solutions that tame the power of LLMs while minimizing potential drawbacks.