
201 reads
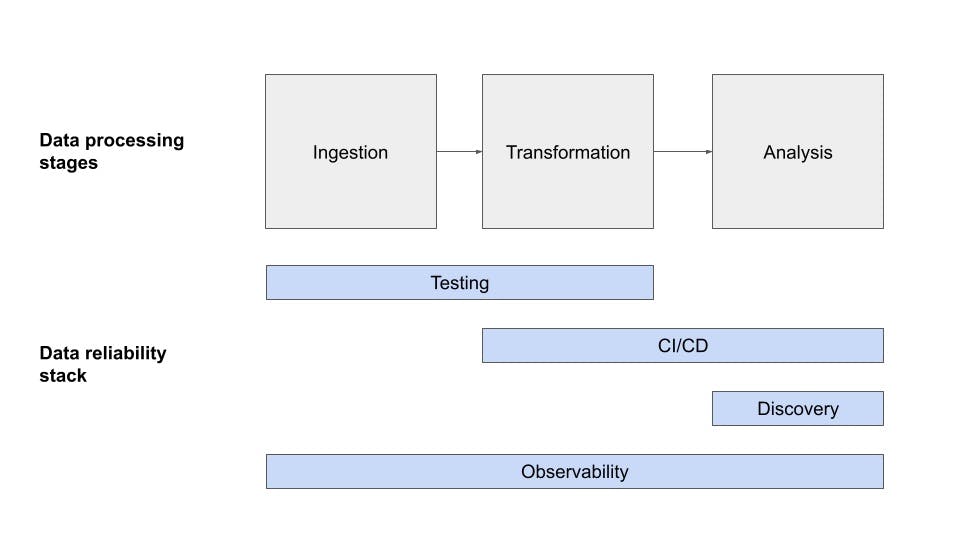
80% of Issues Aren't Caught by Testing Alone: Build Your Data Reliability Stack to Reduce Downtime
by
April 8th, 2022








About Author

CTO and Co-founder, Monte Carlo. Programming wizard and lover of cats.
Comments

TOPICS
THIS ARTICLE WAS FEATURED IN





Related Stories










5 Best Microservices CI/CD Tools You Need to Check Out
@ruchitavarma
Sep 13, 2021