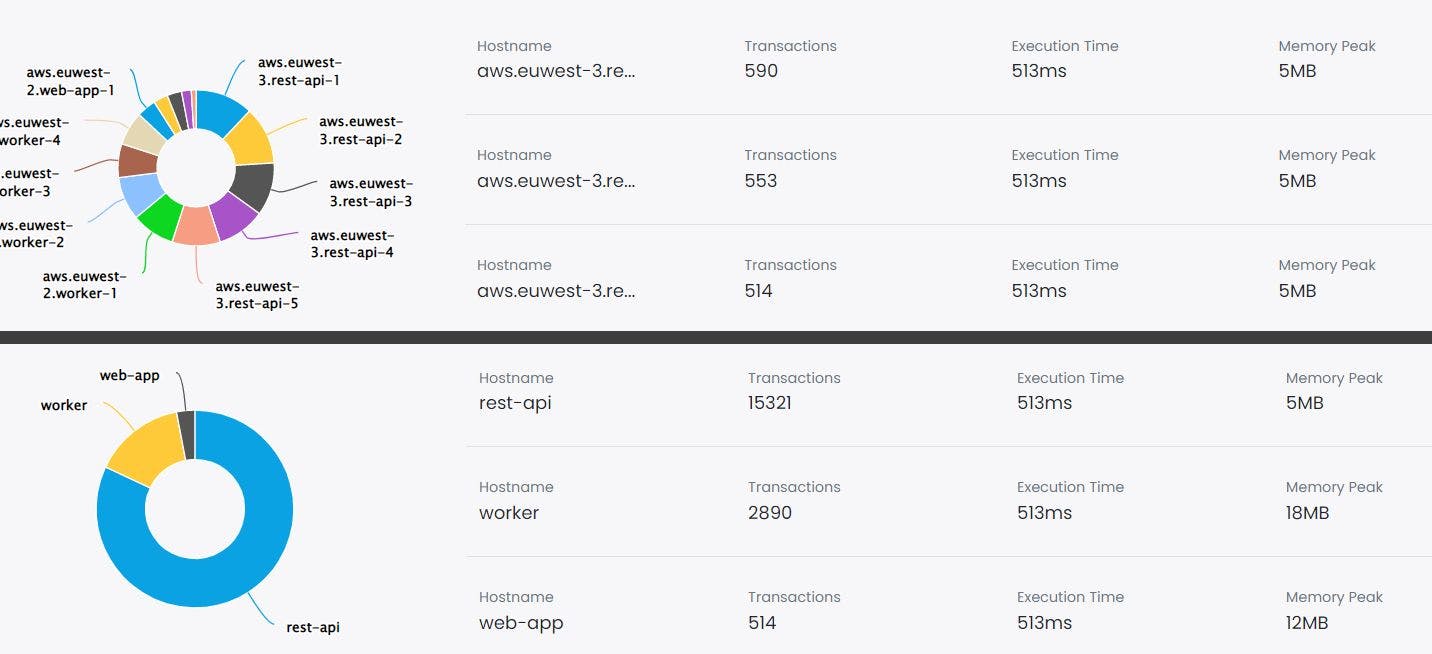
1,212 reads
AWS' Karpenter Autoscaler and How it Stacks Up Against CAST AI
by byCAST AI@CAST.AI
byCAST AI@CAST.AI
AI-driven cloud optimization. Instantly cut your cloud bill, prevent downtime, and 10X the power of DevOps.
December 16th, 2021






Audio Presented by
AI-driven cloud optimization. Instantly cut your cloud bill, prevent downtime, and 10X the power of DevOps.


AI-driven cloud optimization. Instantly cut your cloud bill, prevent downtime, and 10X the power of DevOps.
About Author

AI-driven cloud optimization. Instantly cut your cloud bill, prevent downtime, and 10X the power of DevOps.
Comments