



































































Jan 01, 1970
598 lecturas
Una descripción general digerible de alto nivel de las capacidades de CPU y GPU
Demasiado Largo; Para Leer
El artículo profundiza en las diferencias principales entre CPU y GPU en el manejo de tareas informáticas paralelas, cubriendo conceptos como arquitectura Von Neumann, Hyper-Threading y canalización de instrucciones. Explica la evolución de las GPU desde procesadores gráficos hasta potentes herramientas para acelerar algoritmos de aprendizaje profundo.Una descripción general digerible de alto nivel de lo que sucede en The Die
En este artículo, analizaremos algunos detalles fundamentales de bajo nivel para comprender por qué las GPU son buenas en tareas de gráficos, redes neuronales y aprendizaje profundo y las CPU son buenas en una amplia cantidad de tareas informáticas secuenciales y complejas de propósito general. Hubo varios temas que tuve que investigar y obtener una comprensión un poco más detallada para esta publicación, algunos de los cuales mencionaré de pasada. Se hace deliberadamente para centrarse sólo en los conceptos básicos absolutos del procesamiento de CPU y GPU.
Arquitectura von Neumann
Las computadoras anteriores eran dispositivos dedicados. Los circuitos de hardware y las puertas lógicas se programaron para hacer un conjunto específico de cosas. Si había que hacer algo nuevo, era necesario volver a cablear los circuitos. "Algo nuevo" podría ser tan simple como hacer cálculos matemáticos para dos ecuaciones diferentes. Durante la Segunda Guerra Mundial, Alan Turing estaba trabajando en una máquina programable para vencer a la máquina Enigma y luego publicó el artículo "Turing Machine". Por la misma época, John von Neumann y otros investigadores también estaban trabajando en una idea que proponía fundamentalmente:
- Las instrucciones y los datos deben almacenarse en la memoria compartida (programa almacenado).
- Las unidades de procesamiento y memoria deben estar separadas.
- La unidad de control se encarga de leer datos e instrucciones de la memoria para realizar cálculos utilizando la unidad de procesamiento.
El cuello de botella
- Cuello de botella de procesamiento: solo puede haber una instrucción y su operando a la vez en una unidad de procesamiento (puerta lógica física). Las instrucciones se ejecutan secuencialmente una tras otra. A lo largo de los años, se han realizado mejoras y se ha centrado en hacer procesadores más pequeños, con ciclos de reloj más rápidos y en aumentar el número de núcleos.
- Cuello de botella en la memoria: a medida que los procesadores crecían cada vez más rápido, la velocidad y la cantidad de datos que podían transferirse entre la memoria y la unidad de procesamiento se convertían en un cuello de botella. La memoria es varios órdenes más lenta que la CPU. A lo largo de los años, la atención y las mejoras se han centrado en hacer que la memoria sea más densa y más pequeña.
CPU
Sabemos que todo en nuestra computadora es binario. Cadena, imagen, vídeo, audio, sistema operativo, programa de aplicación, etc., se representan como 1 y 0. Las especificaciones de arquitectura de CPU (RISC, CISC, etc.) tienen conjuntos de instrucciones (x86, x86-64, ARM, etc.) que los fabricantes de CPU deben cumplir y están disponibles para que el sistema operativo interactúe con el hardware.
Los programas del sistema operativo y de aplicación, incluidos los datos, se traducen en conjuntos de instrucciones y datos binarios para procesarlos en la CPU. A nivel de chip, el procesamiento se realiza en transistores y puertas lógicas. Si ejecuta un programa para sumar dos números, la suma (el "procesamiento") se realiza en una puerta lógica en el procesador.
En la CPU según la arquitectura de Von Neumann, cuando sumamos dos números, se ejecuta una única instrucción de suma en dos números en el circuito. ¡Durante una fracción de ese milisegundo, solo se ejecutó la instrucción add en el núcleo (de ejecución) de la unidad de procesamiento! Este detalle siempre me fascinó.
Núcleo en una CPU moderna
Los componentes del diagrama anterior son evidentes. Para obtener más detalles y una explicación detallada, consulte este excelente artículo . En las CPU modernas, un único núcleo físico puede contener más de una ALU entera, ALU de punto flotante, etc. Nuevamente, estas unidades son puertas lógicas físicas.
Necesitamos comprender el 'hilo de hardware' en el núcleo de la CPU para apreciar mejor la GPU. Un subproceso de hardware es una unidad de computación que se puede realizar en unidades de ejecución de un núcleo de CPU, cada ciclo de reloj de la CPU . Representa la unidad de trabajo más pequeña que se puede ejecutar en un núcleo.
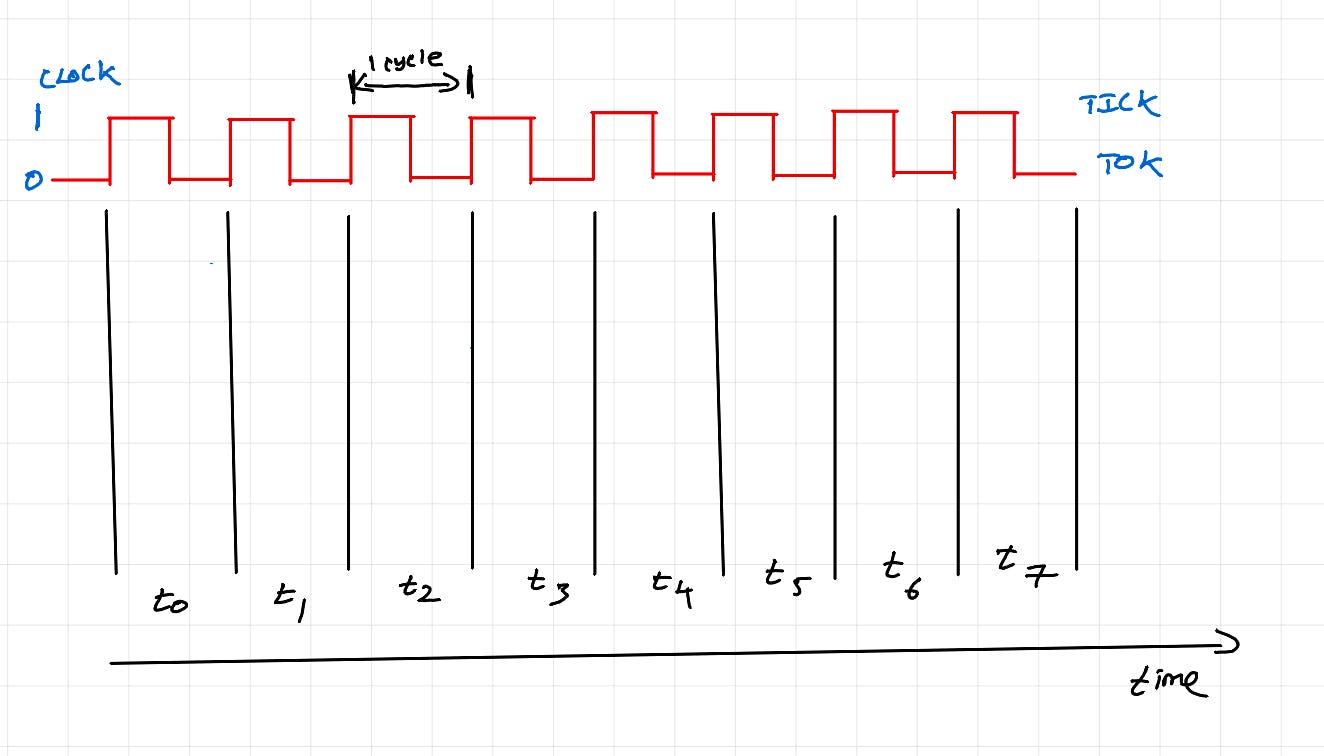
ciclo de instrucción
El diagrama anterior ilustra el ciclo de instrucción de la CPU/ciclo de la máquina. Es una serie de pasos que realiza la CPU para ejecutar una sola instrucción (por ejemplo: c=a+b).
Recuperar: el contador de programa (registro especial en el núcleo de la CPU) realiza un seguimiento de qué instrucción se debe recuperar. La instrucción se recupera y almacena en el registro de instrucciones. Para operaciones simples, también se obtienen los datos correspondientes.
Decodificar: la instrucción se decodifica para ver operadores y operandos.
Ejecutar: según la operación especificada, se elige y ejecuta la unidad de procesamiento adecuada.
Acceso a la memoria: si una instrucción es compleja o se necesitan datos adicionales (varios factores pueden causar esto), el acceso a la memoria se realiza antes de la ejecución. (Se ignora en el diagrama anterior por simplicidad). Para una instrucción compleja, los datos iniciales estarán disponibles en el registro de datos de la unidad de cálculo, pero para la ejecución completa de la instrucción, se requiere acceso a los datos desde la caché L1 y L2. Esto significa que podría haber un pequeño tiempo de espera antes de que se ejecute la unidad de cómputo y el subproceso de hardware aún retenga la unidad de cómputo durante el tiempo de espera.
Reescritura: si la ejecución produce una salida (por ejemplo: c=a+b), la salida se vuelve a escribir en el registro/caché/memoria. (Se ignora en el diagrama anterior o en cualquier lugar posterior de la publicación por simplicidad)
En el diagrama anterior, sólo en t2 se realiza el cálculo. El resto del tiempo, el núcleo simplemente está inactivo (no realizamos ningún trabajo).
Las CPU modernas tienen componentes de hardware que esencialmente permiten que los pasos (buscar-decodificar-ejecutar) se produzcan simultáneamente por ciclo de reloj.
Un único subproceso de hardware ahora puede realizar cálculos en cada ciclo de reloj. Esto se llama canalización de instrucciones.
La recuperación, la decodificación, el acceso a la memoria y la reescritura las realizan otros componentes de una CPU. A falta de una palabra mejor, se denominan "hilos de tubería". El subproceso de canalización se convierte en un subproceso de hardware cuando se encuentra en la etapa de ejecución de un ciclo de instrucción.
Como puede ver, obtenemos resultados de cálculo en cada ciclo desde t2. Anteriormente, obteníamos resultados de cálculo una vez cada 3 ciclos. La canalización mejora el rendimiento informático. Esta es una de las técnicas para gestionar los cuellos de botella de procesamiento en Von Neumann Architecture. También hay otras optimizaciones como ejecución fuera de orden, predicción de rama, ejecución especulativa, etc.
Hyper-Threading
Este es el último concepto que quiero analizar en CPU antes de concluir y pasar a las GPU. A medida que aumentaron las velocidades del reloj, los procesadores también se volvieron más rápidos y eficientes. Con el aumento de la complejidad de las aplicaciones (conjunto de instrucciones), los núcleos de procesamiento de la CPU estaban infrautilizados y pasaban más tiempo esperando el acceso a la memoria.
Entonces, vemos un cuello de botella en la memoria. La unidad de cómputo dedica tiempo al acceso a la memoria y no realiza ningún trabajo útil. La memoria es varios órdenes más lenta que la CPU y la brecha no se cerrará pronto. La idea era aumentar el ancho de banda de la memoria en algunas unidades de un solo núcleo de CPU y mantener los datos listos para utilizar las unidades de cómputo cuando están esperando el acceso a la memoria.
Intel puso a disposición Hyper-threading en 2002 en los procesadores Xeon y Pentium 4. Antes del hyper-threading, solo había un hilo de hardware por núcleo. Con Hyper-Threading, habrá 2 subprocesos de hardware por núcleo. ¿Qué significa? Circuito de procesamiento duplicado para algunos registros, contador de programa, unidad de recuperación, unidad de decodificación, etc.
El diagrama anterior solo muestra nuevos elementos de circuito en un núcleo de CPU con hyperthreading. Es así como un único núcleo físico es visible como 2 núcleos para el Sistema Operativo. Si tenía un procesador de 4 núcleos, con Hyper-Threading habilitado, el sistema operativo lo ve como 8 núcleos . El tamaño de la caché L1 - L3 aumentará para dar cabida a registros adicionales. Tenga en cuenta que las unidades de ejecución son compartidas.
Supongamos que tenemos los procesos P1 y P2 haciendo a=b+c, d=e+f, estos se pueden ejecutar simultáneamente en un solo ciclo de reloj debido a los subprocesos HW 1 y 2. Con un solo subproceso HW, como vimos anteriormente, esto no sería posible. Aquí estamos aumentando el ancho de banda de la memoria dentro de un núcleo agregando subprocesos de hardware para que la unidad de procesamiento se pueda utilizar de manera eficiente. Esto mejora la simultaneidad informática.
Algunos escenarios interesantes:
- La CPU tiene solo una ALU entera. Un subproceso HW 1 o un subproceso HW 2 debe esperar un ciclo de reloj y continuar con el cálculo en el siguiente ciclo.
- La CPU tiene una ALU entera y una ALU de punto flotante. HW Thread 1 y HW Thread 2 pueden realizar sumas simultáneamente usando ALU y FPU respectivamente.
- Todas las ALU disponibles están siendo utilizadas por el subproceso 1 de HW. El subproceso 2 de HW debe esperar hasta que la ALU esté disponible. (No se aplica al ejemplo de suma anterior, pero puede suceder con otras instrucciones).
¿Por qué la CPU es tan buena en la informática tradicional de escritorio/servidor?
- Altas velocidades de reloj: superiores a las velocidades de reloj de la GPU. Al combinar esta alta velocidad con la canalización de instrucciones, las CPU son extremadamente buenas en tareas secuenciales. Optimizado para latencia.
- Diversas aplicaciones y necesidades informáticas: las computadoras personales y los servidores tienen una amplia gama de aplicaciones y necesidades informáticas. Esto da como resultado un conjunto de instrucciones complejo. La CPU tiene que ser buena en varias cosas.
- Multitarea y multiprocesamiento: con tantas aplicaciones en nuestras computadoras, la carga de trabajo de la CPU exige un cambio de contexto. Los sistemas de almacenamiento en caché y el acceso a la memoria están configurados para respaldar esto. Cuando se programa un proceso en el subproceso del hardware de la CPU, tiene todos los datos necesarios listos y ejecuta las instrucciones de cálculo rápidamente una por una.
Desventajas de la CPU
Consulte este artículo y pruebe también el cuaderno Colab . Muestra cómo la multiplicación de matrices es una tarea paralelizable y cómo los núcleos de cómputo paralelos pueden acelerar el cálculo.
- Extremadamente bueno en tareas secuenciales pero no bueno en tareas paralelas.
- Conjunto de instrucciones complejo y patrón de acceso a memoria complejo.
- La CPU también gasta mucha energía en el cambio de contexto y en las actividades de la unidad de control además de la computación.
Conclusiones clave
- La canalización de instrucciones mejora el rendimiento informático.
- Aumentar el ancho de banda de la memoria mejora la simultaneidad informática.
- Las CPU son buenas para tareas secuenciales (optimizadas para latencia). No es bueno para tareas masivamente paralelas, ya que necesita una gran cantidad de unidades informáticas y subprocesos de hardware que no están disponibles (no optimizados para el rendimiento). Estos no están disponibles porque las CPU están diseñadas para informática de uso general y tienen conjuntos de instrucciones complejos.
GPU
A medida que aumentó la potencia informática, también aumentó la demanda de procesamiento de gráficos. Tareas como la representación de la interfaz de usuario y los juegos requieren operaciones paralelas, lo que genera la necesidad de numerosas ALU y FPU a nivel de circuito. Las CPU, diseñadas para tareas secuenciales, no podían manejar estas cargas de trabajo paralelas de manera efectiva. Así, las GPU se desarrollaron para satisfacer la demanda de procesamiento paralelo en tareas gráficas, y luego allanaron el camino para su adopción en la aceleración de algoritmos de aprendizaje profundo.
Recomiendo ampliamente:
- Viendo este que explica las tareas paralelas involucradas en el renderizado de videojuegos.
- Leer esta publicación de blog para comprender las tareas paralelas involucradas en un transformador. También existen otras arquitecturas de aprendizaje profundo como CNN y RNN. Dado que los LLM se están apoderando del mundo, una comprensión de alto nivel del paralelismo en las multiplicaciones de matrices requeridas para las tareas de transformadores establecería un buen contexto para el resto de esta publicación. (Más adelante, planeo comprender completamente los transformadores y compartir una descripción general digerible de alto nivel de lo que sucede en las capas de transformadores de un modelo GPT pequeño).
Muestra de especificaciones de CPU frente a GPU
Los núcleos, los subprocesos de hardware, la velocidad del reloj, el ancho de banda de la memoria y la memoria en el chip de las CPU y GPU difieren significativamente. Ejemplo:
- Intel Xeon 8280 tiene :
- 2700 MHz base y 4000 MHz en Turbo
- 28 núcleos y 56 hilos de hardware
- Subprocesos generales de tubería: 896 - 56
- Caché L3: 38,5 MB (compartido por todos los núcleos) Caché L2: 28,0 MB (dividido entre los núcleos) Caché L1: 1,375 MB (dividido entre los núcleos)
- El tamaño del registro no está disponible públicamente
- Memoria máxima: 1 TB DDR4, 2933 MHz, 6 canales
- Ancho de banda de memoria máximo: 131 GB/s
- Rendimiento máximo de FP64 = 4,0 GHz 2 unidades AVX-512 8 operaciones por unidad AVX-512 por ciclo de reloj * 28 núcleos = ~2,8 TFLOP [Derivado usando: Rendimiento máximo de FP64 = (Frecuencia turbo máxima) (Número de unidades AVX-512) ( Operaciones por unidad AVX-512 por ciclo de reloj) * (Número de núcleos)]
Este número se utiliza para comparar con la GPU, ya que obtener el máximo rendimiento de la informática de uso general es muy subjetivo. Este número es un límite máximo teórico, lo que significa que los circuitos FP64 se están utilizando al máximo.
- Nvidia A100 80GB SXM tiene :
- 1065 MHz base y 1410 MHz en Turbo
- 108 SM, 64 núcleos CUDA FP32 (también llamados SP) por SM, 4 núcleos Tensor FP64 por SM, 68 subprocesos de hardware (64 + 4) por SM
- Total por GPU: 6912 64 núcleos CUDA FP32, 432 núcleos FP 64 Tensor, 7344 (6912 + 432) subprocesos de hardware
- Hilos de tubería por SM: 2048 - 68 = 1980 por SM
- Subprocesos totales de canalización por GPU: (2048 x 108) - (68 x 108) = 21184 - 7344 = 13840
- Consulte: cudaLimitDevRuntimePendingLaunchCount
- Caché L2: 40 MB (compartido entre todos los SM) Caché L1: 20,3 MB en total (192 KB por SM)
- Tamaño de registro: 27,8 MB (256 KB por SM)
- Memoria principal máxima de GPU: 80 GB HBM2e, 1512 MHz
- Ancho de banda máximo de memoria principal de GPU: 2,39 TB/s
- Rendimiento máximo de FP64 = 19,5 TFLOP [usando solo todos los núcleos Tensor FP64]. El valor más bajo de 9,7 TFLOP cuando solo se utiliza FP64 en núcleos CUDA. Este número es un límite máximo teórico, lo que significa que los circuitos FP64 se están utilizando al máximo.
Núcleo en una GPU moderna
Las terminologías que vimos en CPU no siempre se traducen directamente a GPU. Aquí veremos los componentes y el núcleo de la GPU NVIDIA A100. Una cosa que me sorprendió mientras investigaba para este artículo fue que los proveedores de CPU no publican cuántas ALU, FPU, etc. están disponibles en las unidades de ejecución de un núcleo. NVIDIA es muy transparente sobre la cantidad de núcleos y el marco CUDA brinda total flexibilidad y acceso a nivel de circuito.
En el diagrama anterior en GPU, podemos ver que no hay caché L3, caché L2 más pequeña, unidad de control y caché L1 más pequeñas pero con mucha más y una gran cantidad de unidades de procesamiento.
Aquí están los componentes de la GPU en los diagramas anteriores y su equivalente de CPU para nuestra comprensión inicial. No he hecho programación CUDA, por lo que compararla con equivalentes de CPU ayuda con la comprensión inicial. Los programadores de CUDA entienden esto muy bien.
- Múltiples multiprocesadores de transmisión <> CPU multinúcleo
- Transmisión de multiprocesador (SM) <> núcleo de CPU
- Procesador de streaming (SP)/ CUDA Core <> ALU / FPU en unidades de ejecución de un CPU Core
- Tensor Core (capaz de realizar operaciones 4x4 FP64 en una sola instrucción) <> unidades de ejecución SIMD en un núcleo de CPU moderno (por ejemplo: AVX-512)
- Subproceso de hardware (realiza cálculo en CUDA o Tensor Cores en un solo ciclo de reloj) <> Subproceso de hardware (realiza cálculo en unidades de ejecución [ALU, FPU, etc.] en un solo ciclo de reloj)
- Memoria HBM / VRAM / DRAM / GPU <> RAM
- Memoria en chip/SRAM (registros, caché L1, L2) <> Memoria en chip/SRAM (registros, caché L1, L2, L3)
- Nota: Los registros en un SM son significativamente más grandes que los registros en un núcleo. Debido a la gran cantidad de subprocesos. Recuerde que en Hyper-Threading en CPU, vimos un aumento en la cantidad de registros pero no en unidades de cómputo. El mismo principio aquí.
Mover datos y ancho de banda de memoria
Las tareas de gráficos y aprendizaje profundo exigen una ejecución de tipo SIM(D/T) [instrucción única, múltiples datos/hilo]. es decir, leer y trabajar con grandes cantidades de datos para una sola instrucción.
Hablamos sobre la canalización de instrucciones y el hyper-threading en CPU y GPU que también tienen capacidades. La forma en que se implementa y funciona es ligeramente diferente, pero los principios son los mismos.
A diferencia de las CPU, las GPU (a través de CUDA) brindan acceso directo a Pipeline Threads (obteniendo datos de la memoria y utilizando el ancho de banda de la memoria). Los programadores de GPU funcionan primero intentando llenar las unidades de cómputo (incluidos los registros y caché L1 compartidos asociados para almacenar operandos de cómputo), luego "hilos de canalización" que recuperan datos en registros y HBM. Nuevamente, quiero enfatizar que los programadores de aplicaciones de CPU no piensan en esto y no se publican especificaciones sobre "subprocesos de canalización" y la cantidad de unidades de cómputo por núcleo. Nvidia no sólo los publica sino que también proporciona un control total a los programadores.
Entraré en más detalles sobre esto en una publicación dedicada sobre el modelo de programación CUDA y el "procesamiento por lotes" en la técnica de optimización del servicio de modelos, donde podremos ver cuán beneficioso es esto.
El diagrama anterior muestra la ejecución de subprocesos de hardware en el núcleo de CPU y GPU. Consulte la sección "acceso a la memoria" que analizamos anteriormente en canalización de CPU. Este diagrama muestra eso. La compleja gestión de la memoria de la CPU hace que este tiempo de espera sea lo suficientemente pequeño (unos pocos ciclos de reloj) para recuperar datos de la caché L1 en los registros. Cuando es necesario recuperar datos de L3 o de la memoria principal, el otro hilo para el cual los datos ya están registrados (vimos esto en la sección Hyper-Threading) obtiene el control de las unidades de ejecución.
En las GPU, debido a la sobresuscripción (gran número de subprocesos y registros de canalización) y al conjunto de instrucciones simples, ya hay una gran cantidad de datos disponibles en los registros pendientes de ejecución. Estos subprocesos de canalización que esperan ejecución se convierten en subprocesos de hardware y realizan la ejecución con la frecuencia de cada ciclo de reloj, ya que los subprocesos de canalización en las GPU son livianos.
Ancho de banda, intensidad informática y latencia
¿Qué pasa con la portería?
- Utilice al máximo los recursos de hardware (unidades de cómputo) en cada ciclo de reloj para aprovechar al máximo la GPU.
- Para mantener ocupadas las unidades de cómputo, debemos proporcionarles suficientes datos.
Esta es la razón principal por la que la latencia de la multiplicación de matrices más pequeñas es más o menos la misma en CPU y GPU. Pruébalo .
Las tareas deben ser lo suficientemente paralelas y los datos deben ser lo suficientemente grandes como para saturar los FLOP de cómputo y el ancho de banda de la memoria. Si una sola tarea no es lo suficientemente grande, es necesario empaquetar varias tareas para saturar la memoria y la computación para utilizar completamente el hardware.
Intensidad de cálculo = FLOP/ancho de banda . es decir, la relación entre la cantidad de trabajo que pueden realizar las unidades de cómputo por segundo y la cantidad de datos que puede proporcionar la memoria por segundo.
En el diagrama anterior, vemos que la intensidad de la computación aumenta a medida que avanzamos hacia una mayor latencia y una memoria de menor ancho de banda. Queremos que este número sea lo más pequeño posible para que la computación se utilice por completo. Para eso, necesitamos mantener la mayor cantidad de datos en L1/Registros para que el cálculo pueda realizarse rápidamente. Si recuperamos datos únicos de HBM, solo hay unas pocas operaciones en las que realizamos 100 operaciones con datos únicos para que valga la pena. Si no realizamos 100 operaciones, las unidades de cómputo estaban inactivas. Aquí es donde entra en juego una gran cantidad de subprocesos y registros en las GPU. Mantener la mayor cantidad de datos en L1/Registros para mantener baja la intensidad informática y mantener ocupados los núcleos paralelos.
Existe una diferencia en la intensidad de cálculo de 4X entre los núcleos CUDA y Tensor porque los núcleos CUDA solo pueden realizar un MMA FP64 1x1, mientras que los núcleos Tensor pueden realizar instrucciones MMA FP64 4x4 por ciclo de reloj.
Conclusiones clave
Gran cantidad de unidades de cómputo (núcleos CUDA y Tensor), gran cantidad de subprocesos y registros (sobre suscripción), conjunto de instrucciones reducido, sin caché L3, HBM (SRAM), patrón de acceso a memoria simple y de alto rendimiento (en comparación con las CPU: cambio de contexto , almacenamiento en caché multicapa, paginación de memoria, TLB, etc.) son los principios que hacen que las GPU sean mucho mejores que las CPU en computación paralela (renderización de gráficos, aprendizaje profundo, etc.)
Más allá de las GPU
Las GPU se crearon por primera vez para manejar tareas de procesamiento de gráficos. Los investigadores de IA comenzaron a aprovechar CUDA y su acceso directo a un potente procesamiento paralelo a través de núcleos CUDA. La GPU NVIDIA tiene motores de procesamiento de texturas, trazado de rayos, ráster, polimorfismo, etc. (digamos conjuntos de instrucciones específicos de gráficos). Con el aumento en la adopción de la IA, se están agregando núcleos Tensor que son buenos en el cálculo de matrices 4x4 (instrucción MMA) y que están dedicados al aprendizaje profundo.
Desde 2017, NVIDIA ha ido aumentando el número de núcleos Tensor en cada arquitectura. Pero estas GPU también son buenas en el procesamiento de gráficos. Aunque el conjunto de instrucciones y la complejidad son mucho menores en las GPU, no están completamente dedicados al aprendizaje profundo (especialmente la arquitectura Transformer).
FlashAttention 2 , una optimización de la capa de software (simpatía mecánica por el patrón de acceso a la memoria de la capa de atención) para la arquitectura del transformador proporciona una aceleración del doble en las tareas.
Con nuestra comprensión profunda de CPU y GPU basada en los primeros principios, podemos comprender la necesidad de aceleradores de transformadores: un chip dedicado (circuito solo para operaciones de transformadores), con una cantidad incluso mayor de unidades de cómputo para paralelismo, conjunto de instrucciones reducido, sin Cachés L1/L2, DRAM (registros) masivos que reemplazan a HBM, unidades de memoria optimizadas para el patrón de acceso a la memoria de la arquitectura del transformador. Después de todo, los LLM son nuevos compañeros para los humanos (después de la web y los dispositivos móviles) y necesitan chips dedicados para lograr eficiencia y rendimiento.
Algunos aceleradores de IA:
Aceleradores de transformadores:
Aceleradores de transformadores basados en FPGA:
Referencias:
- https://en.wikipedia.org/wiki/Von_Neumann_architecture
- https://chsasank.com/llm-system-design.html
- https://www.redhat.com/sysadmin/cpu-components-functionality
- https://docs.wixstatic.com/ugd/56440f_e458602dcb0c4af9aaeb7fdaa34bb2b4.pdf
- https://www.nand2tetris.org/course
- https://cpu.land/
- https://en.wikipedia.org/wiki/Hyper-threading
- ¿Cómo funcionan los gráficos de videojuegos? -
- CPU frente a GPU frente a TPU frente a DPU frente a QPU - https://www.youtube.com/watch?v=r5NQecwZs1A
- Cómo funciona la computación GPU | GTC 2021 | Stephen Jones: https://www.nvidia.com/en-us/on-demand/session/gtcspring21-s31151/
- Intensidad de cálculo: https://www.linkedin.com/pulse/threads-tensor-cores-beyond-unveiling-dynamics-gpu-memory-florit-smg2c/
- Cómo funciona la programación CUDA | GTC Otoño 2022 | Stephen Jones: https://www.nvidia.com/en-us/on-demand/session/gtcfall22-a41101/
- ¿Por qué utilizar GPU con redes neuronales? - https://www.youtube.com/watch?v=GRRMi7UfZHg
- Hardware CUDA | Tom Nurkkala | Conferencia de la Universidad de Taylor: https://www.youtube.com/watch?v=kUqkOAU84bA
- https://ashanpriyadarshana.medium.com/cuda-gpu-memory-architecture-8c3ac644bd64
- https://colab.research.google.com/drive/1nw34aks9SdMwHXl9Gf5T9GPxRB9BIIyr
- https://developer.nvidia.com/blog/cuda-refresher-reviewing-the-origins-of-gpu-computing/
L O A D I N G
. . . comments & more!
. . . comments & more!



