













































Jan 01, 1970
1,660 讀數
新的多 LLM 策略提高了情绪分析的准确性
太長; 讀書
用于情绪分析的多 LLM 协商框架使用生成器-鉴别器模型来迭代优化决策,从而克服单轮限制。这种方法提高了各种基准测试(包括 Twitter 和电影评论)的性能。作者:
(1) 孙晓飞,浙江大学;
(2)李晓雅,Shannon.AI和字节跳动;
(3) 张胜宇,浙江大学;
(4) 王树和,北京大学;
(5)吴飞,浙江大学;
(6)李继伟,浙江大学;
(7)张天伟,南洋理工大学;
(8)王国印,Shannon.AI和字节跳动。
链接表
抽象的
情绪分析的标准范例是依靠单个 LLM,并在上下文学习框架下单轮做出决策。该框架的关键缺点是单个 LLM 生成的单轮输出可能无法提供完美的决策,就像人类有时需要多次尝试才能做出正确的决定一样。对于情绪分析任务尤其如此,因为需要深度推理来解决输入中的复杂语言现象(例如,子句构成、反讽等)。
为了解决这个问题,本文介绍了一种用于情感分析的多 LLM 协商框架。该框架由一个注入推理的生成器组成,用于提供决策和理由,以及一个解释推导鉴别器,用于评估生成器的可信度。生成器和鉴别器不断迭代,直到达成共识。所提出的框架自然解决了上述挑战,因为我们能够利用两个 LLM 的互补能力,让它们使用理由来说服对方进行纠正。
在广泛的情绪分析基准(SST-2、电影评论、Twitter、yelp、亚马逊、IMDB)上进行的实验证明了所提方法的有效性:它在所有基准上始终比 ICL 基线产生更好的性能,甚至在 Twitter 和电影评论数据集上比监督基线产生更好的性能。
1 简介
情感分析 (Pang and Lee, 2008; Go et al., 2009; Maas et al., 2011a; Zhang and Liu, 2012; Baccianella et al., 2010; Medhat et al., 2014; Bakshi et al., 2016; Zhang et al., 2018) 旨在提取一段文本所表达的观点极性。大型语言模型 (LLM) 的最新进展 (Brown et al., 2020; Ouyang et al., 2022; Touvron et al., 2023a,b; Anil et al., 2023; Zeng et al., 2022b; OpenAI, 2023; Bai et al., 2023) 为解决该任务打开了一扇新的大门 (Lu et al., 2021; Kojima et al., 2022; Wang et al., 2022b; Wei et al., 2022b; Wan et al., 2023; Wang et al., 2023; Sun et al., 2023b,a; Lightman et al., 2023; Li et al., 2023; Schick et al., 2023):在上下文学习 (ICL) 范式,LLM 仅使用少量训练示例就能实现与监督学习策略 (Lin et al., 2021; Sun et al., 2021; Phan and Ogunbona, 2020; Dai et al., 2021) 相当的性能。
现有的利用 LLM 进行情感分析的方法通常依赖于单个 LLM,并在 ICL 下在一轮中做出决策。这种策略存在以下缺点:单个 LLM 生成的单轮输出可能无法提供完美的响应:正如人类有时需要多次尝试才能正确处理一样,LLM 可能需要多轮才能做出正确的决定。对于情感分析任务尤其如此,其中 LLM 通常需要阐明推理过程以解决输入句子中的复杂语言现象(例如,子句组成、反讽等)。
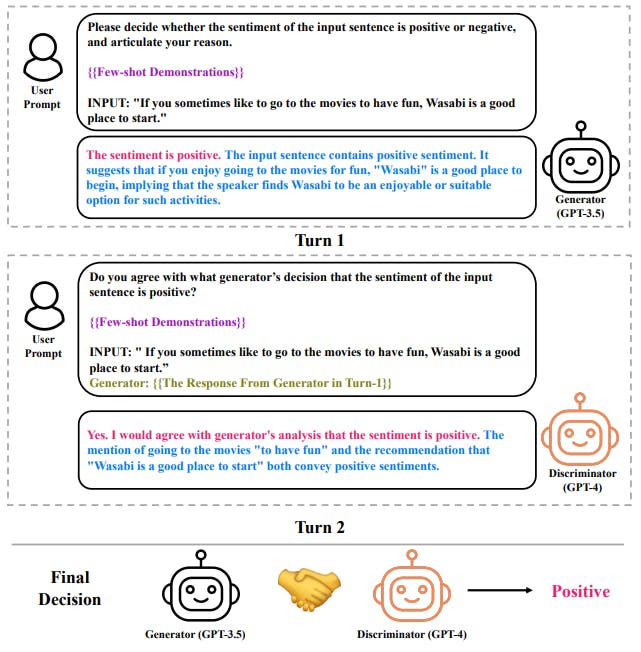
针对该问题,本文提出了一种用于情绪分析的多 LLM 协商策略。该策略的核心是一个生成器-鉴别器框架,其中一个 LLM 充当生成器(G)来产生情绪决策,而另一个 LLM 充当鉴别器(D),负责评估第一个 LLM 生成输出的可信度。所提出的方法在三个方面进行了创新:(1)推理注入生成器(G):遵循结构化推理链的 LLM,增强生成器的 ICL,同时为鉴别器提供评估其有效性的证据和见解;(2)基于解释的鉴别器(D);另一个 LLM 旨在为其判断提供后评估理由;(3)协商:两个 LLM 分别充当生成器和鉴别器的角色,并进行协商直至达成共识。
这种策略充分利用了两个 LLM 的集体能力,为模型提供了纠正不完美响应的渠道,从而自然解决了单个 LLM 无法在第一次尝试时做出正确决策的问题。
这项工作的贡献可以概括如下:1)我们提供了一个关于情绪分析如何从多 LLM 协商中受益的新颖视角。2)我们引入了一个生成器-鉴别器角色转换决策框架,该框架通过迭代生成和验证情绪分类来实现多 LLM 协作。3)我们的实证结果为所提出方法的有效性提供了证据:在广泛的情绪分析基准(SST-2、电影评论、Twitter、yelp、亚马逊、IMDB)上进行的实验表明,所提出的方法在所有基准上始终比 ICL 基线产生更好的性能,甚至优于 Twitter 和电影评论数据集上的监督基线。
L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
標籤
Languages
相關故事

有毒管理者破坏生产力和团队合作的 4 个习惯 #toxic-workplaces
Jan 01, 1970

为什么美容和时尚行业是 AR 和空间计算的未来 #augmented-reality
Jan 01, 1970

