













































Jan 01, 1970
1,660 lượt đọc
Chiến lược Multi-LLM mới tăng cường độ chính xác trong phân tích tình cảm
dài quá đọc không nổi
Khung đàm phán đa LLM để phân tích cảm tính sử dụng mô hình phân biệt đối xử tạo ra để tinh chỉnh lặp đi lặp lại các quyết định, khắc phục các hạn chế trong một lượt. Cách tiếp cận này cải thiện hiệu suất trên nhiều tiêu chuẩn khác nhau, bao gồm cả Twitter và các bài đánh giá phim.tác giả:
(1) Xiaofei Sun, Đại học Chiết Giang;
(2) Xiaoya Li, Shannon.AI và Bytedance;
(3) Shengyu Zhang, Đại học Chiết Giang;
(4) Shuhe Wang, Đại học Bắc Kinh;
(5) Fei Wu, Đại học Chiết Giang;
(6) Jiwei Li, Đại học Chiết Giang;
(7) Tianwei Zhang, Đại học Công nghệ Nanyang;
(8) Guoyin Wang, Shannon.AI và Bytedance.
Bảng liên kết
Đàm phán LLM để phân tích tình cảm
Kết luận và tài liệu tham khảo
trừu tượng
Một mô hình tiêu chuẩn để phân tích cảm tính là dựa vào LLM đơn lẻ và đưa ra quyết định trong một vòng duy nhất trong khuôn khổ học tập trong ngữ cảnh. Khung này gặp phải nhược điểm chính là đầu ra một lượt do một LLM duy nhất tạo ra có thể không mang lại quyết định hoàn hảo, giống như con người đôi khi cần nhiều nỗ lực để giải quyết mọi việc đúng đắn. Điều này đặc biệt đúng đối với nhiệm vụ phân tích tình cảm, trong đó cần phải có lý luận sâu sắc để giải quyết hiện tượng ngôn ngữ phức tạp (ví dụ: thành phần mệnh đề, hàm ý mỉa mai, v.v.) trong đầu vào.
Để giải quyết vấn đề này, bài viết này giới thiệu một khuôn khổ đàm phán đa LLM để phân tích tình cảm. Khung này bao gồm một trình tạo được truyền vào lý luận để đưa ra quyết định cùng với cơ sở lý luận, một bộ phân biệt đối xử dẫn xuất giải thích để đánh giá độ tin cậy của trình tạo. Trình tạo và trình phân biệt đối xử lặp đi lặp lại cho đến khi đạt được sự đồng thuận. Khung đề xuất đã giải quyết được thách thức nói trên một cách tự nhiên, vì chúng tôi có thể tận dụng các khả năng bổ sung của hai LLM, yêu cầu họ sử dụng lý do để thuyết phục lẫn nhau sửa chữa.
Các thử nghiệm trên nhiều tiêu chuẩn phân tích tình cảm (SST-2, Movie Review, Twitter, yelp, amazon, IMDB) chứng minh tính hiệu quả của phương pháp được đề xuất: nó luôn mang lại hiệu suất tốt hơn so với đường cơ sở ICL trên tất cả các điểm chuẩn và thậm chí hiệu suất vượt trội so với đường cơ sở được giám sát trên Twitter và bộ dữ liệu đánh giá phim.
1. Giới thiệu
Phân tích tình cảm (Pang và Lee, 2008; Go và cộng sự, 2009; Maas và cộng sự, 2011a; Zhang và Liu, 2012; Baccianella và cộng sự, 2010; Medhat và cộng sự, 2014; Bakshi và cộng sự, 2016; Zhang và cộng sự, 2018) nhằm mục đích rút ra sự phân cực về quan điểm được thể hiện bằng một đoạn văn bản. Những tiến bộ gần đây trong các mô hình ngôn ngữ lớn (LLM) (Brown và cộng sự, 2020; Ouyang và cộng sự, 2022; Touvron và cộng sự, 2023a,b; Anil và cộng sự, 2023; Zeng và cộng sự, 2022b; OpenAI, 2023 ; Bai và cộng sự, 2023) mở ra cánh cửa mới cho việc giải quyết nhiệm vụ (Lu và cộng sự, 2021; Kojima và cộng sự, 2022; Wang và cộng sự, 2022b; Wei và cộng sự, 2022b; Wan và cộng sự. , 2023; Wang và cộng sự, 2023; Sun và cộng sự, 2023b,a; Lightman và cộng sự, 2023; Li và cộng sự, 2023; Schick và cộng sự, 2023): theo mô hình học tập trong ngữ cảnh ( ICL), LLM có thể đạt được hiệu suất tương đương với các chiến lược học tập có giám sát (Lin và cộng sự, 2021; Sun và cộng sự, 2021; Phan và Ogunbona, 2020; Dai và cộng sự, 2021) chỉ với một số ít ví dụ đào tạo .
Các phương pháp tiếp cận hiện tại khai thác LLM để phân tích cảm tính thường dựa vào một LLM đơn lẻ và đưa ra quyết định trong một vòng duy nhất theo ICL. Chiến lược này gặp phải nhược điểm sau: đầu ra một lượt do một LLM duy nhất tạo ra có thể không mang lại phản hồi hoàn hảo: Giống như con người đôi khi cần nhiều nỗ lực để làm mọi việc đúng đắn, có thể phải mất nhiều vòng trước khi LLM đưa ra quyết định đúng đắn. Điều này đặc biệt đúng đối với nhiệm vụ phân tích tình cảm, trong đó LLM thường cần trình bày rõ ràng quá trình lý luận để giải quyết hiện tượng ngôn ngữ phức tạp (ví dụ: thành phần mệnh đề, châm biếm, v.v.) trong câu đầu vào.
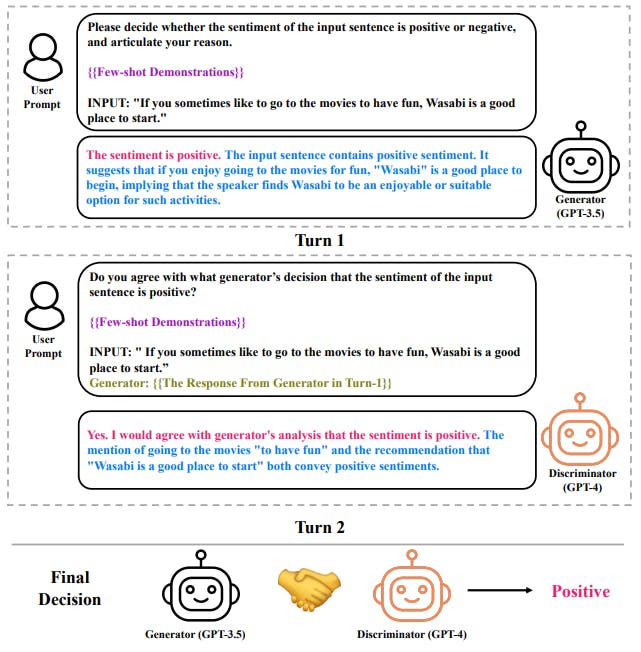
Để giải quyết vấn đề này, trong bài viết này, chúng tôi đề xuất chiến lược đàm phán nhiều LLM để phân tích tình cảm. Cốt lõi của chiến lược được đề xuất là khung phân biệt đối xử của người tạo, trong đó một LLM đóng vai trò là người tạo ra (G) để đưa ra các quyết định về cảm tính, trong khi LLM kia đóng vai trò là người phân biệt đối xử (D), có nhiệm vụ đánh giá độ tin cậy của đầu ra được tạo ra từ LLM đầu tiên. Phương pháp được đề xuất đổi mới trên ba khía cạnh: (1) Trình tạo dựa trên lý luận (G): một LLM tuân thủ chuỗi lý luận có cấu trúc, nâng cao ICL của trình tạo đồng thời cung cấp cho người phân biệt đối xử bằng chứng và hiểu biết sâu sắc để đánh giá tính hợp lệ của nó; (2) Bộ phân biệt đối xử dẫn đến giải thích (D); LLM khác được thiết kế để đưa ra các lý do căn bản sau đánh giá cho các đánh giá của nó; (3) Đàm phán: hai LLM đóng vai trò là người tạo ra và người phân biệt đối xử và thực hiện đàm phán cho đến khi đạt được sự đồng thuận.
Chiến lược này khai thác khả năng tập thể của hai LLM và cung cấp kênh cho mô hình để sửa các phản hồi không hoàn hảo và do đó giải quyết một cách tự nhiên vấn đề rằng một LLM duy nhất không thể đưa ra quyết định chính xác trong lần thử đầu tiên.
Những đóng góp của công việc này có thể được tóm tắt như sau: 1) chúng tôi cung cấp một góc nhìn mới về cách phân tích tình cảm có thể hưởng lợi từ việc đàm phán nhiều LLM. 2) chúng tôi giới thiệu khung Ra quyết định chuyển đổi vai trò của Người tạo-Người phân biệt đối xử cho phép cộng tác nhiều LLM thông qua việc tạo và xác thực các phân loại cảm tính theo cách lặp đi lặp lại. 3) các phát hiện thực nghiệm của chúng tôi đưa ra bằng chứng về tính hiệu quả của phương pháp được đề xuất: các thử nghiệm trên nhiều tiêu chuẩn phân tích cảm tính (SST-2, Movie Review, Twitter, yelp, amazon, IMDB) chứng minh rằng phương pháp được đề xuất luôn mang lại hiệu suất tốt hơn so với đường cơ sở ICL trên tất cả các điểm chuẩn và thậm chí có hiệu suất vượt trội so với đường cơ sở được giám sát trên Twitter và bộ dữ liệu đánh giá phim.
Bài viết này có sẵn trên arxiv theo giấy phép CC 4.0.
L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
chuyên mục
Languages
NHỮNG BÀI VIẾT LIÊN QUAN
581 Stories To Learn About Non Fiction
#non-fiction

178 Stories To Learn About Essay #essay
Jan 01, 1970

94 Stories To Learn About John Locke #john-locke
Jan 01, 1970

