













































Jan 01, 1970
1,660 測定値
新しいマルチLLM戦略により感情分析の精度が向上
長すぎる; 読むには
感情分析のためのマルチ LLM 交渉フレームワークは、ジェネレーター ディスクリミネーター モデルを使用して、単一ターンの制限を克服しながら、決定を反復的に改良します。このアプローチにより、Twitter や映画レビューなどのさまざまなベンチマークでパフォーマンスが向上します。著者:
(1)浙江大学の孫暁飛氏
(2)シャオヤ・リー、Shannon.AI、Bytedance
(3)浙江大学の張聖宇氏
(4)王淑和、北京大学
(5)浙江大学の呉飛氏
(6)浙江大学の李継偉氏
(7)南洋理工大学の張天偉氏
(8)Guoyin Wang、Shannon.AI、Bytedance。
リンク一覧
抽象的な
感情分析の標準的なパラダイムは、単一の LLM に依存し、コンテキスト内学習のフレームワークの下で 1 ラウンドで決定を下すことです。このフレームワークには、人間が物事を正しく理解するために複数回の試行を必要とすることがあるのと同じように、単一の LLM によって生成された 1 ターンの出力では完璧な決定が下されない可能性があるという大きな欠点があります。これは、入力内の複雑な言語現象 (例: 節の構成、皮肉など) に対処するために深い推論が必要な感情分析のタスクに特に当てはまります。
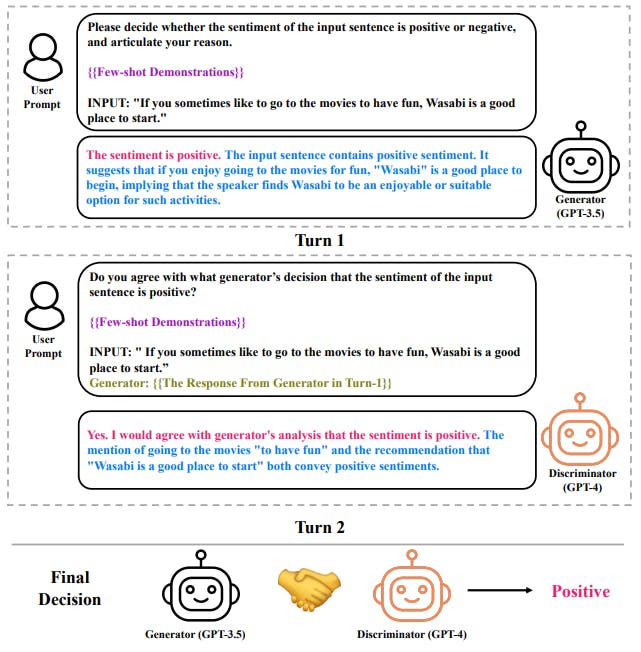
この問題に対処するため、本論文では感情分析のためのマルチ LLM 交渉フレームワークを紹介します。このフレームワークは、決定と根拠を提供する推論を組み込んだジェネレータと、ジェネレータの信頼性を評価する説明を導出する識別器で構成されています。ジェネレータと識別器は、合意に達するまで繰り返します。提案されたフレームワークは、2 つの LLM の補完的な機能を活用して、根拠を使用して互いに修正を説得できるため、前述の課題に自然に対処しました。
幅広い感情分析ベンチマーク (SST-2、映画レビュー、Twitter、yelp、amazon、IMDB) での実験により、提案されたアプローチの有効性が実証されています。すべてのベンチマークで ICL ベースラインよりも一貫して優れたパフォーマンスが得られ、Twitter および映画レビュー データセットでは教師ありベースラインよりも優れたパフォーマンスが得られます。
1 はじめに
感情分析 (Pang and Lee, 2008; Go et al., 2009; Maas et al., 2011a; Zhang and Liu, 2012; Baccianella et al., 2010; Medhat et al., 2014; Bakshi et al., 2016; Zhang et al., 2018) は、テキストのチャンクによって表現された意見の極性を抽出することを目的としています。大規模言語モデル(LLM)の最近の進歩(Brown et al., 2020; Ouyang et al., 2022; Touvron et al., 2023a,b; Anil et al., 2023; Zeng et al., 2022b; OpenAI, 2023; Bai et al., 2023)は、タスクを解決するための新たな扉を開きます(Lu et al., 2021; Kojima et al., 2022; Wang et al., 2022b; Wei et al., 2022b; Wan et al., 2023; Wang et al., 2023; Sun et al., 2023b,a; Lightman et al., 2023; Li et al., 2023; Schick et al., 2023年): コンテキスト内学習(ICL)のパラダイムの下で、LLMは、少数のトレーニング例のみで、教師あり学習戦略(Lin et al.、2021; Sun et al.、2021; Phan and Ogunbona、2020; Dai et al.、2021)に匹敵するパフォーマンスを達成できます。
感情分析に LLM を利用する既存のアプローチは、通常、単一の LLM に依存し、ICL の下で 1 ラウンドで決定を下します。この戦略には、次の欠点があります。単一の LLM によって生成される 1 ターンの出力では、完璧な応答が得られない可能性があります。人間が物事を正しく理解するために複数回の試行が必要になることがあるのと同様に、LLM が正しい決定を下すまでに複数ラウンドかかる場合があります。これは感情分析のタスクに特に当てはまります。感情分析では、LLM は通常、入力文の複雑な言語現象 (節の構成、皮肉など) に対処するために推論プロセスを明確にする必要があります。
この問題に対処するため、本稿では、感情分析のためのマルチ LLM 交渉戦略を提案する。提案戦略の中核はジェネレーター - ディスクリミネーター フレームワークであり、1 つの LLM が感情決定を生成するジェネレーター (G) として機能し、もう 1 つの LLM がディスクリミネーター (D) として機能し、最初の LLM から生成された出力の信頼性を評価するタスクを担う。提案手法は、次の 3 つの側面で革新的である。(1) 推論を組み込んだジェネレーター (G): 構造化された推論チェーンに準拠し、ジェネレーターの ICL を強化すると同時に、ディスクリミネーターにその妥当性を評価するための証拠と洞察を提供する LLM。(2) 説明を導き出すディスクリミネーター (D): 評価後の判断の根拠を提供するように設計された他の LLM。(3) 交渉: 2 つの LLM がジェネレーターとディスクリミネーターの役割を果たし、合意に達するまで交渉を実行する。
この戦略は、2 つの LLM の総合的な能力を活用し、モデルが不完全な応答を修正するためのチャネルを提供することで、単一の LLM が最初の試行で正しい決定を下すことができないという問題を自然に解決します。
この研究の貢献は、次のようにまとめることができます。1) 感情分析がマルチ LLM ネゴシエーションからどのように恩恵を受けるかについて、新しい視点を提供します。2) 感情分類を繰り返し生成および検証することでマルチ LLM コラボレーションを可能にする、ジェネレーターと識別子の役割を切り替える意思決定フレームワークを紹介します。3) 実証的な調査結果は、提案されたアプローチの有効性の証拠を提供します。幅広い感情分析ベンチマーク (SST-2、映画レビュー、Twitter、yelp、amazon、IMDB) での実験では、提案された方法がすべてのベンチマークで ICL ベースラインよりも一貫して優れたパフォーマンスをもたらし、Twitter および映画レビュー データセットでは教師ありベースラインよりも優れたパフォーマンスをもたらすことが実証されています。
この論文はCC 4.0ライセンスの下でarxivで公開されています。
L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
ラベル
Languages
関連ストーリー
効果的なプロンプトを作成し、AIを最大限に活用する方法
#writing-prompts


経済予測の再定義: insytz のアルゴリズムが大不況を予測できた可能性 #economics
Jan 01, 1970

