













































Jan 01, 1970
1,670 lecturas
La nueva estrategia Multi-LLM aumenta la precisión en el análisis de sentimiento
Demasiado Largo; Para Leer
Un marco de negociación de múltiples LLM para el análisis de sentimientos utiliza un modelo generador-discriminador para refinar las decisiones de forma iterativa, superando las limitaciones de un solo turno. Este enfoque mejora el rendimiento en varios puntos de referencia, incluidos Twitter y reseñas de películas.Autores:
(1) Xiaofei Sun, Universidad de Zhejiang;
(2) Xiaoya Li, Shannon.AI y Bytedance;
(3) Shengyu Zhang, Universidad de Zhejiang;
(4) Shuhe Wang, Universidad de Pekín;
(5) Fei Wu, Universidad de Zhejiang;
(6) Jiwei Li, Universidad de Zhejiang;
(7) Tianwei Zhang, Universidad Tecnológica de Nanyang;
(8) Guoyin Wang, Shannon.AI y Bytedance.
Tabla de enlaces
Negociación LLM para análisis de sentimiento
Abstracto
Un paradigma estándar para el análisis de sentimientos es confiar en un LLM singular y tomar la decisión en una sola ronda bajo el marco del aprendizaje en contexto. Este marco sufre la desventaja clave de que la salida de un solo turno generada por un solo LLM podría no ofrecer la decisión perfecta, del mismo modo que los humanos a veces necesitan múltiples intentos para hacer las cosas bien. Esto es especialmente cierto para la tarea de análisis de sentimientos, donde se requiere un razonamiento profundo para abordar el complejo fenómeno lingüístico (por ejemplo, composición de cláusulas, ironía, etc.) en la entrada.
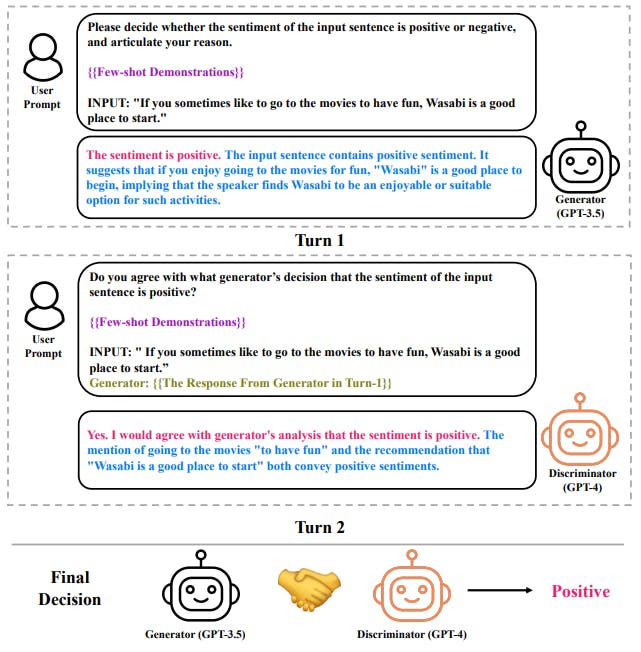
Para abordar este problema, este artículo presenta un marco de negociación de múltiples LLM para el análisis de sentimiento. El marco consiste en un generador infundido de razonamiento para proporcionar decisiones junto con la justificación, un discriminador que deriva explicaciones para evaluar la credibilidad del generador. El generador y el discriminador se iteran hasta llegar a un consenso. El marco propuesto, naturalmente, abordó el desafío antes mencionado, ya que podemos tomar las habilidades complementarias de dos LLM y hacer que utilicen fundamentos para persuadirse mutuamente para la corrección.
Los experimentos en una amplia gama de puntos de referencia de análisis de sentimiento (SST-2, Movie Review, Twitter, yelp, amazon, IMDB) demuestran la efectividad del enfoque propuesto: produce consistentemente mejores desempeños que la base de referencia ICL en todos los puntos de referencia, e incluso desempeños superiores a líneas de base supervisadas en los conjuntos de datos de Twitter y reseñas de películas.
1. Introducción
Análisis de sentimiento (Pang y Lee, 2008; Go et al., 2009; Maas et al., 2011a; Zhang y Liu, 2012; Baccianella et al., 2010; Medhat et al., 2014; Bakshi et al., 2016; Zhang et al., 2018) tiene como objetivo extraer la polaridad de opinión expresada en un fragmento de texto. Avances recientes en modelos de lenguaje grande (LLM) (Brown et al., 2020; Ouyang et al., 2022; Touvron et al., 2023a,b; Anil et al., 2023; Zeng et al., 2022b; OpenAI, 2023 ; Bai et al., 2023) abren una nueva puerta para la resolución de la tarea (Lu et al., 2021; Kojima et al., 2022; Wang et al., 2022b; Wei et al., 2022b; Wan et al. , 2023; Wang et al., 2023; Sun et al., 2023b,a; Lightman et al., 2023; Schick et al., 2023): bajo el paradigma del aprendizaje en contexto ( ICL), los LLM pueden lograr desempeños comparables a las estrategias de aprendizaje supervisado (Lin et al., 2021; Sun et al., 2021; Phan y Ogunbona, 2020; Dai et al., 2021) con solo una pequeña cantidad de ejemplos de capacitación. .
Los enfoques existentes que aprovechan los LLM para el análisis de sentimiento generalmente se basan en un LLM singular y toman una decisión en una sola ronda bajo ICL. Esta estrategia tiene la siguiente desventaja: el resultado de un solo turno generado por un solo LLM puede no ofrecer la respuesta perfecta: así como los humanos a veces necesitan múltiples intentos para hacer las cosas bien, pueden ser necesarias varias rondas antes de que un LLM tome la decisión correcta. Esto es especialmente cierto para la tarea de análisis de sentimientos, donde los LLM generalmente necesitan articular el proceso de razonamiento para abordar el fenómeno lingüístico complejo (por ejemplo, composición de cláusulas, ironía, etc.) en la oración de entrada.
Para abordar este problema, en este artículo proponemos una estrategia de negociación de múltiples LLM para el análisis de sentimiento. El núcleo de la estrategia propuesta es un marco generador-discriminador, donde un LLM actúa como generador (G) para producir decisiones de sentimiento, mientras que el otro actúa como discriminador (D), encargado de evaluar la credibilidad del resultado generado a partir del primer LLM. El método propuesto innova en tres aspectos: (1) Generador de razonamiento (G): un LLM que se adhiere a una cadena de razonamiento estructurado, mejorando el ICL del generador al tiempo que ofrece al discriminador la evidencia y los conocimientos para evaluar su validez; (2) Discriminador derivado de explicaciones (D); otro LLM diseñado para ofrecer fundamentos posteriores a la evaluación de sus juicios; (3) Negociación: dos LLM actúan como generador y discriminador, y realizan la negociación hasta que se alcanza un consenso.
Esta estrategia aprovecha las habilidades colectivas de los dos LLM y proporciona el canal para que el modelo corrija respuestas imperfectas y, por lo tanto, resuelve naturalmente el problema de que un solo LLM no puede generar la decisión correcta en su primer intento.
Las contribuciones de este trabajo se pueden resumir de la siguiente manera: 1) proporcionamos una perspectiva novedosa sobre cómo el análisis de sentimientos puede beneficiarse de la negociación multi-LLM. 2) presentamos un marco de toma de decisiones de cambio de roles Generador-Discriminador que permite la colaboración de varios LLM mediante la generación y validación iterativas de categorizaciones de sentimientos. 3) nuestros hallazgos empíricos ofrecen evidencia de la eficacia del enfoque propuesto: experimentos en una amplia gama de puntos de referencia de análisis de sentimiento (SST-2, Movie Review, Twitter, yelp, amazon, IMDB) demuestran que el método propuesto produce consistentemente mejores rendimientos que la línea de base de ICL en todos los puntos de referencia, e incluso desempeños superiores a las líneas de base supervisadas en los conjuntos de datos de Twitter y reseñas de películas.
Este documento está disponible en arxiv bajo licencia CC 4.0.
L O A D I N G
. . . comments & more!
. . . comments & more!



