173 reads
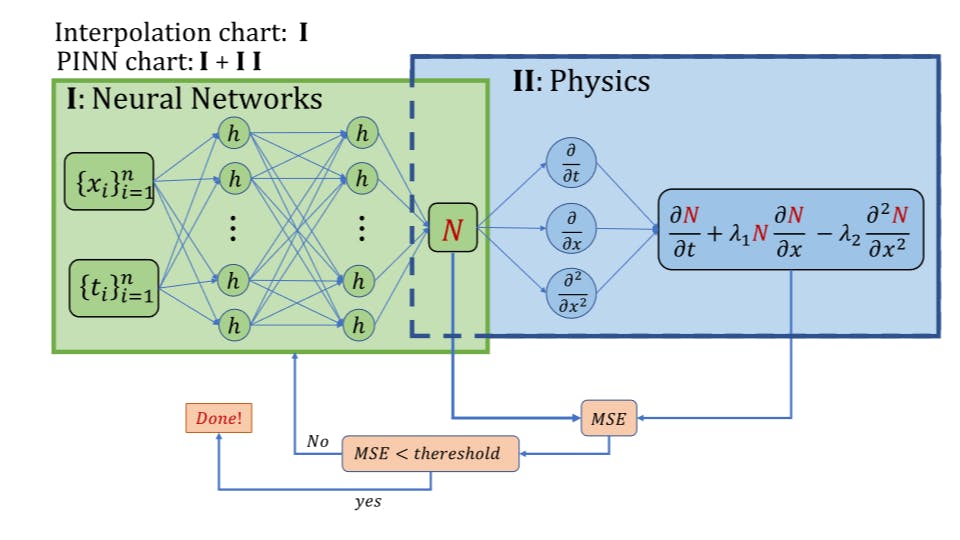
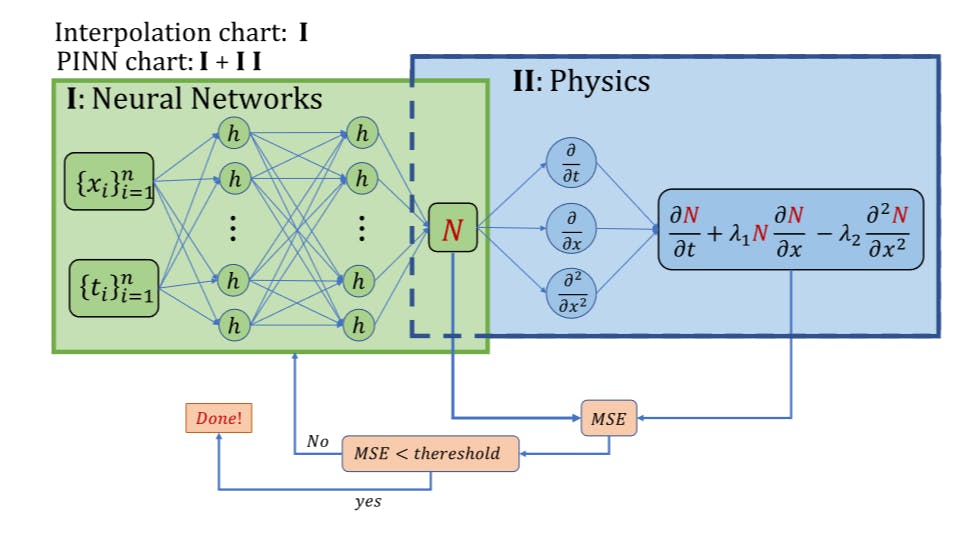
Physics-Informed with Power-Enhanced Residual Network: Residual Network
by byThe Interpolation Publication@interpolation
byThe Interpolation Publication@interpolation
#1 Publication focused exclusively on Interpolation, ie determining value from the existing values in a given data set.
February 28th, 2024






#1 Publication focused exclusively on Interpolation, ie determining value from the existing values in a given data set.


#1 Publication focused exclusively on Interpolation, ie determining value from the existing values in a given data set.
About Author

#1 Publication focused exclusively on Interpolation, ie determining value from the existing values in a given data set.
Comments