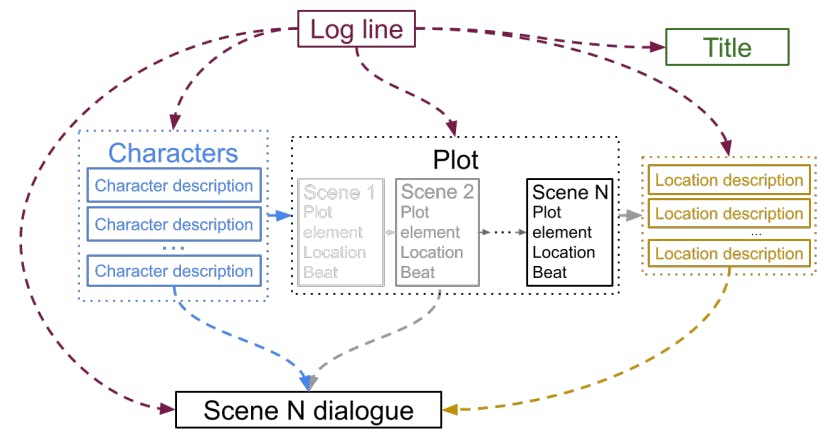
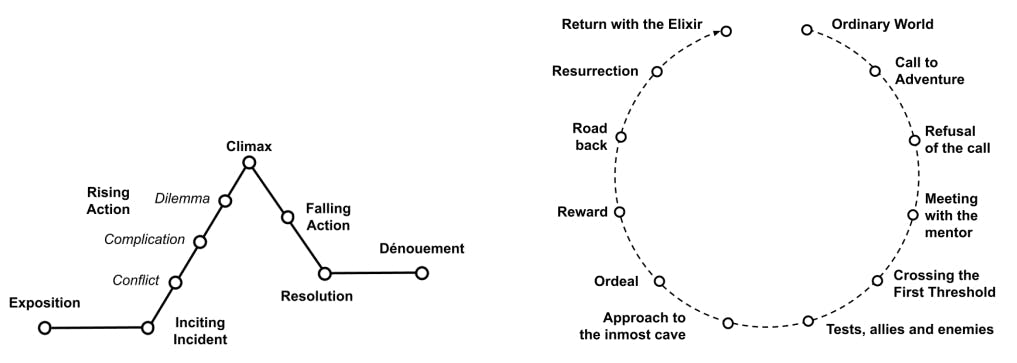
394 reads
What Users Say About Dramaton’s AI Writing Tool
by byTeleplay Technology @teleplay
byTeleplay Technology @teleplay
From teleplay to technology, we weave a narrative tapestry that dances between writing, CGI, and "action!"
May 21st, 2024






From teleplay to technology, we weave a narrative tapestry that dances between writing, CGI, and "action!"
Story's Credibility


From teleplay to technology, we weave a narrative tapestry that dances between writing, CGI, and "action!"
Story's Credibility
About Author

From teleplay to technology, we weave a narrative tapestry that dances between writing, CGI, and "action!"
Comments