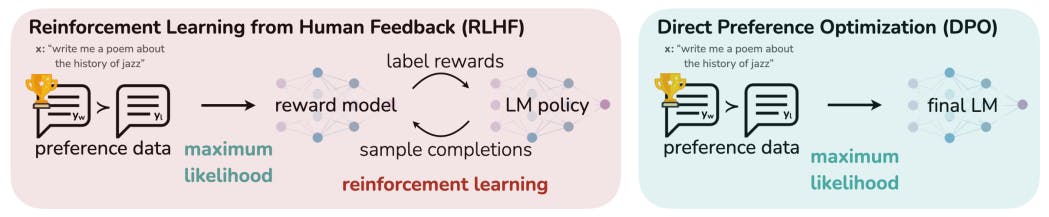
Direct Preference Optimization (DPO) is a novel fine-tuning technique that has become popular due to its simplicity and ease of implementation. It has emerged as a direct alternative to (RLHF) for large language model (LLM) fine-tuning to align with human preferences attributable to its stability, performance, and computational lightweight nature, eliminating the need for sampling from the LM during fine-tuning. DPO can achieve performance levels as well as or better than existing methods. reinforcement learning from human feedback Unlike existing methods that involve leveraging RLHF, DPO reframes the language alignment process as a simple loss function that can be directly optimized using a dataset of preferences {(x,yw,yl)}, where: • x is a prompt • yw is a preferred method • yl is a rejected method Unlike RLHF which requires responses to be sampled from a language model during the optimization process, in DPO, the responses need not be sampled from the LM being optimized. How does DPO Work? The working process of DPO can be divided into two steps. In this step, the model is fine-tuned on the relevant data. Supervised Fine-tuning (SFT): The model is fine-tuned on preference data ideally sourced from the same distribution as the SFT examples. Preference learning: Unlike RLHF, in which a reward model is trained first for policy optimization, DPO directly adds preference information into the optimization process without the intermediate step of training a reward model. DPO uses LLM as a reward model and employs a binary cross-entropy objective to optimize the policy, leveraging human preference data to identify which responses are preferred and which are not. The policy is adjusted based on the preferred responses to boost its performance. Supervised Fine-tuning We aid you in developing Generative AI applications for LLMs so that they are versatile and adaptive to specific use cases. This involves providing data or examples to the model to learn and adapt, hence we offer prompt engineering solutions for design, testing, deployment, and delivery of prompts. Cogito. In supervised fine-tuning (SFT), that provide a clear mapping between specific inputs and desired outputs. Supervised Fine-tuning, especially with preference learning, is employed to shape or adjust the model’s outputs to match criteria defined by humans, ensuring that they closely align with specific requirements. LLM is trained on labeled datasets Preference Data in NLP Preference data refers to a carefully chosen set of options or alternatives concerning a specific prompt. Annotators evaluate these options in accordance with certain guidelines. The overall process aims to rank these options from the most to the least preferred based on human preferences. The ranking is then used to fine-tune models to generate outputs in line with human expectations. How to Create Preference Data Prompt Selection The prompt is the cornerstone of preference data. There are several ways of selecting prompts — some choose a predefined set, while others use templates to generate prompts dynamically or opt for a combination of predefined prompts with random ones taken from the database. Response Selection The next step is to determine the output in response to the prompt. These responses can be generated from a well-trained version of a model or various checkpoints in the model’s development. Not all responses generated are the same, ranking of answers can vary. In the binary ranking system, each answer is simply categorized as either "best" or "worst," whereas a granular ranking system assigns a score (e.g., 1-5) to each answer, allowing for a more detailed and nuanced evaluation. Annotation Guidelines Annotation guidelines are essential to ensure that the ranking systems are standardized to minimize individual biases and interpretations. Benefits of DPO DPO has many advantages over RLHF as follows: Simplicity and Ease of Implementation Unlike the multi-layered process of collecting detailed feedback, optimizing complex policy, and reward model training, DPO directly integrates human preference into the training loop. This approach not only eliminates the complexity associated with the process but also better aligns with the standard systems of pre-training and fine-tuning. Moreover, DPO doesn’t involve navigating the intricacies of constructing and adjusting reward functions. RLHF that involves No Need for Reward Model Training DPO eliminates the need to train an additional reward model, saving computational resources and removing the challenges associated with reward model accuracy and maintenance. Developing an efficient reward model that interprets human feedback into actionable signals for AI is a complex task. It requires substantial effort and needs regular updates to reflect evolving human preferences accurately. DPO bypasses this step entirely by directly leveraging preference data for model improvement. Superior Performance DPO can be as good or even better than other methods, like RLHF (Reinforcement Learning from Human Feedback) and PPO (Proximal Policy Optimization), to improve the performance of large language models according to a research titled . Direct Preference Optimization: Your Language Model is Secretly a Reward Model Conclusion Direct performance optimization is a stable and efficient fine-tuning technique that doesn't require excessive computational resources. Unlike RLHF, DPO doesn’t need a complex reward model and sampling from the language model during fine-tuning. It is not just a new algorithm but a game changer in AI model fine-tuning, simplifying, and enhancing the process of building language models that better understand and cater to human needs.