












































Jan 01, 1970
1,528 讀數
为什么视觉变形金刚专注于无聊的背景?
太長; 讀書
视觉变换器 (ViT) 在图像相关任务中广受欢迎,但表现出奇怪的行为:专注于不重要的背景块而不是图像中的主要主题。研究人员发现,一小部分具有异常高 L2 规范的补丁令牌导致了这些注意力的激增。他们假设 ViT 回收低信息补丁来存储全局图像信息,从而导致了这种行为。为了解决这个问题,他们建议添加“注册”令牌来提供专用存储,从而获得更平滑的注意力图、更好的性能并提高对象发现能力。这项研究强调了持续研究模型工件以提高变压器能力的必要性。
Transformer 已成为许多视觉任务的首选模型架构。视觉变形金刚 (ViT) 特别受欢迎。他们将转换器直接应用于图像块序列。 ViT 现在在图像分类等基准方面匹配或超过了 CNN。然而,Meta 和 INRIA 的研究人员在 ViT 的内部运作中发现了一些奇怪的现象。
在这篇文章中,我们将深入探讨
神秘的注意力激增
许多先前的工作都赞扬视觉转换器生成平滑、可解释的注意力图。这些让我们可以了解模型正在关注图像的哪些部分。
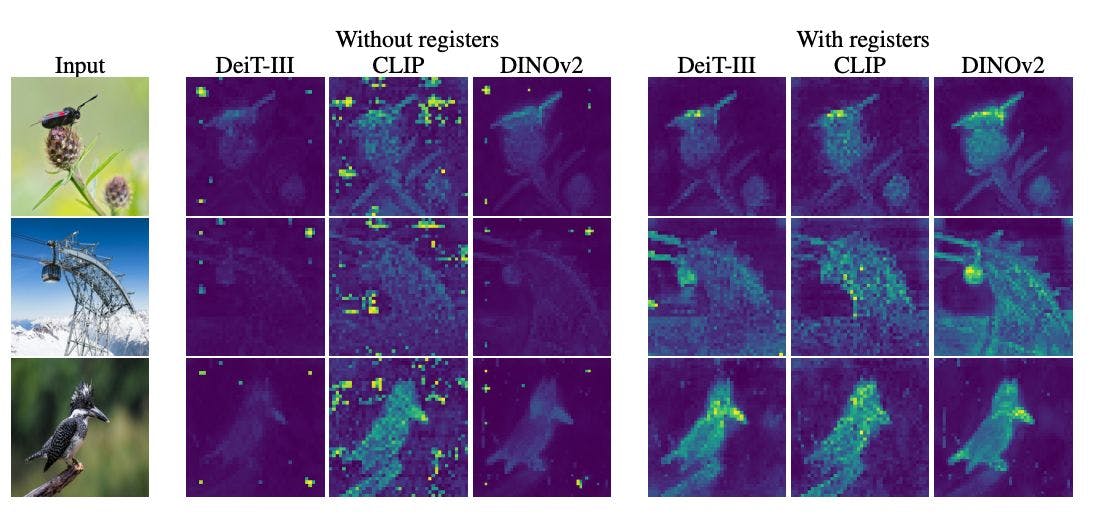
奇怪的是,许多 ViT 变体在随机、无信息的背景补丁上表现出高度关注。为什么这些模型如此关注无聊、不重要的背景元素,而不是这些图像的主要主题?
通过可视化跨模型的注意力图并创建像上面这样的图像,研究人员明确地表明这种情况在 DeiT 和 CLIP 等监督版本以及 DINOv2 等较新的自我监督模型中发生。
显然,某些因素导致模型莫名其妙地关注背景噪声。但什么?
追踪原因:高范数异常标记
通过对输出嵌入进行数值探测,作者确定了根本原因。一小部分(约 2%)的补丁代币具有异常高的 L2 规范,使它们成为极端异常值。
在神经网络的背景下,神经元的权重和偏差可以表示为向量。向量的 L2 范数(也称为欧几里得范数)是其大小的度量,计算为其元素平方和的平方根。
当我们说一个向量(例如,神经元或层的权重)具有“异常高的 L2 范数”时,这意味着该向量的大小或长度与给定上下文中的预期或典型值相比异常大。
神经网络中的高 L2 规范可以表明以下几个问题:
过度拟合:如果模型与训练数据拟合得太紧密并捕获噪声,则权重可能会变得非常大。像 L2 正则化这样的正则化技术会惩罚大的权重来缓解这种情况。
数值不稳定:非常大或非常小的权重可能会导致数值问题,从而导致模型不稳定。
泛化能力差:高 L2 规范还可能表明该模型可能无法很好地泛化到新的、未见过的数据。
用简单的英语来说这是什么意思?想象一下,您正在尝试平衡跷跷板,并且在两侧放置了不同尺寸的重物(或沙袋)。每个袋子的尺寸代表了它在平衡跷跷板方面的影响力或重要性。现在,如果其中一个袋子异常大(具有较高的“L2 范数”),则意味着该袋子对平衡的影响太大。
在神经网络的背景下,如果其中一个部分具有异常高的影响力(高 L2 范数),它可能会掩盖其他重要部分,从而导致错误的决策或过度依赖特定特征。这并不理想,我们经常尝试调整机器以确保没有任何单个零件产生太大的不当影响。
这些高范数标记直接对应于注意力图中的尖峰。因此,模型出于未知原因选择性地突出显示这些补丁。
额外的实验表明:
- 异常值仅在训练足够大的模型期间出现。
- 他们大约在训练进行到一半时出现。
- 它们出现在与其邻居高度相似的斑块上,表明存在冗余。
此外,虽然异常值保留的有关其原始补丁的信息较少,但它们对完整图像类别的预测能力更强。
这个证据指向了一个有趣的理论......
回收假说
作者假设,当模型在 ImageNet-22K 等大型数据集上进行训练时,它们会学会识别低信息补丁,这些补丁的值可以在不丢失图像语义的情况下被丢弃。
然后,该模型回收这些补丁嵌入来存储有关完整图像的临时全局信息,丢弃不相关的局部细节。这允许高效的内部特征处理。
然而,这种回收会导致不良的副作用:
- 丢失原始补丁细节,损害分割等密集任务
- 难以解释的尖锐注意力图
- 与对象发现方法不兼容
因此,虽然这种行为是自然出现的,但它会产生负面后果。
使用显式寄存器修复 ViT
为了减少回收的补丁,研究人员建议通过在序列中添加“注册”标记来为模型提供专用存储。这为内部计算提供了临时的暂存空间,防止随机补丁嵌入被劫持。
值得注意的是,这个简单的调整效果非常好。
使用寄存器训练的模型显示:
- 更平滑、语义更有意义的注意力图
- 各种基准测试的性能略有提升
- 大大提高了对象发现能力
寄存器为回收机制提供了一个合适的家,消除了其令人讨厌的副作用。只需进行一个小的架构更改即可带来显着的收益。
要点
这项有趣的研究提供了一些有价值的见解:
- 视觉转换器会产生不可预见的行为,例如回收补丁进行存储
- 添加寄存器提供临时暂存空间,防止意外的副作用
- 这个简单的修复改进了注意力图和下游性能
- 可能还有其他未被发现的模型工件需要调查
窥探神经网络黑匣子内部可以揭示其内部运作原理,指导渐进式改进。更多类似的工作将稳步提高变压器的能力。
视觉变形器的快速进展并没有显示出放缓的迹象。我们生活在激动人心的时代!
也发布在这里。
L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
標籤
Languages
相關故事
庆祝战争机器人十周年并从技术角度进行反思
#game-development

初创企业的产品市场契合技巧:20 位专家的见解 #product-marketing
Jan 01, 1970

闭上眼睛,想象科技的未来:设备交响曲 #future-of-tech
Jan 01, 1970

