















































Jan 01, 1970
1,118 lượt đọc
ColBERT giúp nhà phát triển vượt qua giới hạn của RAG như thế nào
dài quá đọc không nổi
Tìm hiểu về ColBERT, một cách mới để chấm điểm mức độ liên quan của đoạn văn bằng cách sử dụng mô hình ngôn ngữ BERT giúp giải quyết đáng kể các vấn đề liên quan đến việc truy xuất đoạn văn dày đặc.
Thế hệ tăng cường truy xuất (RAG) hiện là một phần tiêu chuẩn của các ứng dụng trí tuệ nhân tạo tổng quát (AI). Việc bổ sung lời nhắc ứng dụng của bạn với ngữ cảnh liên quan được truy xuất từ cơ sở dữ liệu vectơ có thể tăng đáng kể độ chính xác và giảm ảo giác. Điều này có nghĩa là mức độ liên quan ngày càng tăng trong kết quả tìm kiếm vectơ có mối tương quan trực tiếp với chất lượng ứng dụng RAG của bạn.
Có hai lý do khiến RAG vẫn phổ biến và ngày càng phù hợp ngay cả khi các mô hình ngôn ngữ lớn (LLM) tăng cửa sổ ngữ cảnh của chúng :
Thời gian phản hồi LLM và giá cả đều tăng tuyến tính theo độ dài ngữ cảnh.
LLM vẫn gặp khó khăn với cả khả năng truy xuất và lý luận trong các bối cảnh lớn.
Nhưng RAG không phải là cây đũa thần. Đặc biệt, thiết kế phổ biến nhất, truy xuất đoạn văn dày đặc (DPR), biểu thị cả truy vấn và đoạn văn dưới dạng một vectơ nhúng duy nhất và sử dụng độ tương tự cosine đơn giản để cho điểm mức độ liên quan. Điều này có nghĩa là DPR phụ thuộc rất nhiều vào mô hình nhúng có bề dày đào tạo để nhận ra tất cả các cụm từ tìm kiếm có liên quan.
Thật không may, các mô hình có sẵn gặp khó khăn với các thuật ngữ bất thường, bao gồm cả tên, không phổ biến trong dữ liệu huấn luyện của chúng. DPR cũng có xu hướng quá nhạy cảm với chiến lược phân đoạn, điều này có thể khiến một đoạn văn có liên quan bị bỏ sót nếu nó bị bao quanh bởi nhiều thông tin không liên quan. Tất cả những điều này tạo ra gánh nặng cho nhà phát triển ứng dụng trong việc “làm đúng ngay lần đầu tiên”, bởi vì một lỗi thường dẫn đến việc phải xây dựng lại chỉ mục từ đầu.
Giải quyết các thách thức của DPR với ColBERT
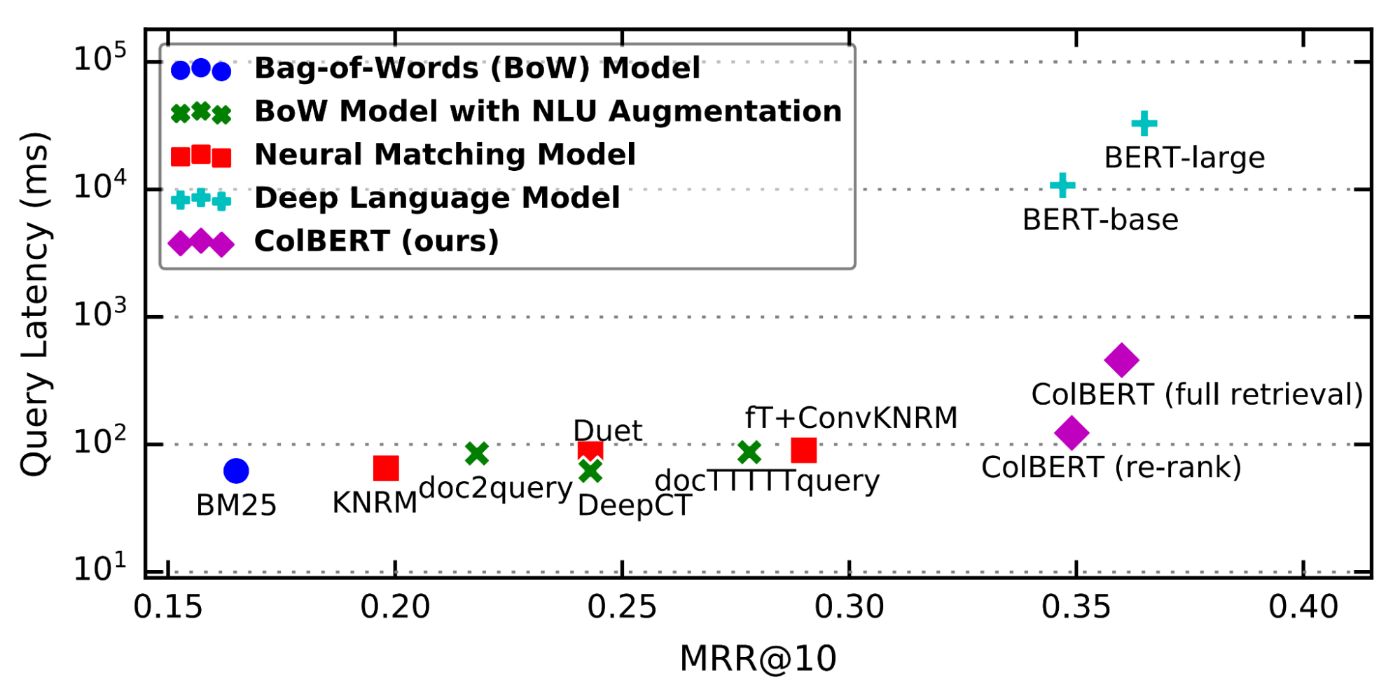
ColBERT là một cách mới để chấm điểm mức độ liên quan của đoạn văn bằng cách sử dụng mô hình ngôn ngữ BERT nhằm giải quyết đáng kể các vấn đề với DPR. Sơ đồ này từ bài báo ColBERT đầu tiên cho thấy lý do tại sao nó lại thú vị đến vậy:
Điều này so sánh hiệu suất của ColBERT với các giải pháp tiên tiến khác cho bộ dữ liệu MS-MARCO. (MS-MARCO là một tập hợp các truy vấn Bing mà Microsoft đã chấm điểm các đoạn văn có liên quan nhất bằng tay. Đây là một trong những tiêu chuẩn truy xuất tốt hơn.) Thấp hơn và bên phải là tốt hơn.
Nói tóm lại, ColBERT vượt trội hơn hẳn trong lĩnh vực hầu hết các giải pháp phức tạp hơn đáng kể với cái giá phải trả là độ trễ tăng lên một chút.
Để kiểm tra điều này, tôi đã tạo một bản demo và lập chỉ mục hơn 1.000 bài viết trên Wikipedia bằng cả ada002 DPR và ColBERT. Tôi thấy rằng ColBERT mang lại kết quả tốt hơn đáng kể đối với các cụm từ tìm kiếm bất thường.
Ảnh chụp màn hình sau đây cho thấy DPR không nhận ra cái tên bất thường của William H. Herndon, một cộng sự của Abraham Lincoln, trong khi ColBERT tìm thấy tài liệu tham khảo trong bài báo của Springfield. Cũng lưu ý rằng kết quả số 2 của ColBERT dành cho một William khác, trong khi không có kết quả nào của DPR có liên quan.
ColBERT thường được mô tả bằng những thuật ngữ máy học dày đặc, nhưng thực ra nó rất đơn giản. Tôi sẽ trình bày cách triển khai truy xuất và tính điểm ColBERT trên DataStax Astra DB chỉ với một vài dòng Python và Ngôn ngữ truy vấn Cassandra (CQL).
Ý tưởng lớn
Thay vì DPR dựa trên một vectơ truyền thống, biến các đoạn văn thành một vectơ “nhúng” duy nhất, ColBERT tạo ra một vectơ chịu ảnh hưởng theo ngữ cảnh cho mỗi mã thông báo trong các đoạn văn. ColBERT tạo vectơ tương tự cho từng mã thông báo trong truy vấn.
(Mã thông báo đề cập đến việc chia đầu vào thành các phần nhỏ của từ trước khi được LLM xử lý. Andrej Karpathy, thành viên sáng lập của nhóm OpenAI, vừa phát hành một video nổi bật về cách hoạt động của tính năng này .)
Sau đó, điểm của mỗi tài liệu là tổng độ tương tự tối đa của mỗi truy vấn được nhúng vào bất kỳ phần nhúng tài liệu nào:
def maxsim(qv, document_embeddings): return max(qv @ dv for dv in document_embeddings) def score(query_embeddings, document_embeddings): return sum(maxsim(qv, document_embeddings) for qv in query_embeddings)
(@ là toán tử PyTorch cho tích số chấm và là thước đo phổ biến nhất về độ tương tự của vectơ .)
Vậy là xong - bạn có thể triển khai tính điểm ColBERT trong bốn dòng Python! Bây giờ bạn hiểu ColBERT hơn 99% số người đăng bài về nó trên X (trước đây gọi là Twitter).
Phần còn lại của các bài viết ColBERT đề cập đến:
- Làm cách nào để tinh chỉnh mô hình BERT để tạo ra các phần nhúng tốt nhất cho một tập dữ liệu nhất định?
- Làm cách nào để bạn giới hạn bộ tài liệu mà bạn tính điểm (tương đối đắt) được hiển thị ở đây?
Câu hỏi đầu tiên là tùy chọn và nằm ngoài phạm vi của bài viết này. Tôi sẽ sử dụng điểm kiểm tra ColBERT đã được huấn luyện trước. Nhưng cách thứ hai rất dễ thực hiện với cơ sở dữ liệu vectơ như DataStax Astra DB.
ColBERT trên Astra DB
Có một thư viện Python tất cả trong một phổ biến dành cho ColBERT có tên RAGatouille ; tuy nhiên, nó giả định một tập dữ liệu tĩnh. Một trong những tính năng mạnh mẽ của ứng dụng RAG là đáp ứng dữ liệu thay đổi linh hoạt theo thời gian thực . Vì vậy, thay vào đó, tôi sẽ sử dụng chỉ mục vectơ của Astra để thu hẹp tập hợp tài liệu tôi cần để cho điểm xuống những ứng cử viên tốt nhất cho mỗi vectơ con.
Có hai bước khi thêm ColBERT vào ứng dụng RAG: nhập và truy xuất.
Nhập
Vì mỗi đoạn tài liệu sẽ có nhiều phần nhúng được liên kết với nó nên tôi sẽ cần hai bảng:
CREATE TABLE chunks ( title text, part int, body text, PRIMARY KEY (title, part) ); CREATE TABLE colbert_embeddings ( title text, part int, embedding_id int, bert_embedding vector<float, 128>, PRIMARY KEY (title, part, embedding_id) ); CREATE INDEX colbert_ann ON colbert_embeddings(bert_embedding) WITH OPTIONS = { 'similarity_function': 'DOT_PRODUCT' };
Sau khi cài đặt thư viện ColBERT ( pip install colbert-ai ) và tải xuống điểm kiểm tra BERT đã được huấn luyện trước , tôi có thể tải tài liệu vào các bảng sau:
from colbert.infra.config import ColBERTConfig from colbert.modeling.checkpoint import Checkpoint from colbert.indexing.collection_encoder import CollectionEncoder from cassandra.concurrent import execute_concurrent_with_args from db import DB def encode_and_save(title, passages): db = DB() cf = ColBERTConfig(checkpoint='checkpoints/colbertv2.0') cp = Checkpoint(cf.checkpoint, colbert_config=cf) encoder = CollectionEncoder(cf, cp) # encode_passages returns a flat list of embeddings and a list of how many correspond to each passage embeddings_flat, counts = encoder.encode_passages(passages) # split up embeddings_flat into a nested list start_indices = [0] + list(itertools.accumulate(counts[:-1])) embeddings_by_part = [embeddings_flat[start:start+count] for start, count in zip(start_indices, counts)] # insert into the database for part, embeddings in enumerate(embeddings_by_part): execute_concurrent_with_args(db.session, db.insert_colbert_stmt, [(title, part, i, e) for i, e in enumerate(embeddings)])
(Tôi muốn gói gọn logic DB của mình trong một mô-đun chuyên dụng; bạn có thể truy cập toàn bộ nguồn trong kho GitHub của tôi.)
Truy xuất
Sau đó, quá trình truy xuất trông như thế này:
def retrieve_colbert(query): db = DB() cf = ColBERTConfig(checkpoint='checkpoints/colbertv2.0') cp = Checkpoint(cf.checkpoint, colbert_config=cf) encode = lambda q: cp.queryFromText([q])[0] query_encodings = encode(query) # find the most relevant documents for each query embedding. using a set # handles duplicates so we don't retrieve the same one more than once docparts = set() for qv in query_encodings: rows = db.session.execute(db.query_colbert_ann_stmt, [list(qv)]) docparts.update((row.title, row.part) for row in rows) # retrieve these relevant documents and score each one scores = {} for title, part in docparts: rows = db.session.execute(db.query_colbert_parts_stmt, [title, part]) embeddings_for_part = [tensor(row.bert_embedding) for row in rows] scores[(title, part)] = score(query_encodings, embeddings_for_part) # return the source chunk for the top 5 return sorted(scores, key=scores.get, reverse=True)[:5]
Đây là truy vấn đang được thực thi cho phần tài liệu có liên quan nhất ( db.query_colbert_ann_stmt ):
SELECT title, part FROM colbert_embeddings ORDER BY bert_embedding ANN OF ? LIMIT 5
Ngoài những điều cơ bản: RAGStack
Bài viết này và kho lưu trữ được liên kết giới thiệu ngắn gọn cách hoạt động của ColBERT. Bạn có thể thực hiện điều này ngay hôm nay bằng dữ liệu của riêng mình và xem kết quả ngay lập tức. Giống như mọi thứ trong AI, các phương pháp hay nhất đang thay đổi hàng ngày và các kỹ thuật mới liên tục xuất hiện.
Để giúp việc theo kịp công nghệ tiên tiến trở nên dễ dàng hơn, DataStax đang triển khai cải tiến này và các cải tiến khác vào RAGStack , thư viện RAG sẵn sàng sản xuất của chúng tôi tận dụng LangChain và LlamaIndex. Mục tiêu của chúng tôi là cung cấp cho các nhà phát triển một thư viện nhất quán cho các ứng dụng RAG giúp họ kiểm soát việc nâng cấp chức năng mới. Thay vì phải theo kịp vô số thay đổi về kỹ thuật và thư viện, bạn có một luồng duy nhất để có thể tập trung vào việc xây dựng ứng dụng của mình. Bạn có thể sử dụng RAGStack ngay hôm nay để kết hợp các phương pháp thực hành tốt nhất cho LangChain và LlamaIndex ngay lập tức; những tiến bộ như ColBERT sẽ đến với RAGstack trong các bản phát hành sắp tới.
Bởi Jonathan Ellis, DataStax
Cũng xuất hiện ở đây .
L O A D I N G
. . . comments & more!
. . . comments & more!



