





5,368 reads
The Next Era of AI: Inside the Breakthrough GPT-4 Model





Too Long; Didn't Read
GPT-4 represents a major leap forward in large language model capabilities. It builds on the architecture and strengths of GPT-3 while achieving new levels of scale and performance. The model card provides transparency into the model's training data, intended uses, capabilities and more.




GPT-4 represents a major leap forward in large language model capabilities. Developed by OpenAI, it builds on the architecture and strengths of GPT-3 while achieving new levels of scale and performance.
This article summarizes the key details about GPT-4 based on currently available public information.
Model Stats
-
Total parameters: ~1.8 trillion parameters (over 10x more than GPT-3)
-
Architecture: Uses a mixture of experts (MoE) model to improve scalability
-
Training compute: Trained on ~25,000 Nvidia A100 GPUs over 90-100 days
-
Training data: Trained on a dataset of ~13 trillion tokens
-
Context length: Supports up to 32,000 tokens of context
Model Card
The GPT-4 model card provides transparency into the model's training data, intended uses, capabilities, limitations and more.
- Model type: Transformer with Mixture-of-Experts
- Training data: Web text, books, Wikipedia, Reddit, Amazon reviews
- Intended uses: Text generation, QA, classification, conversational agents
- Capabilities: Text generation, QA, classification
- Modalities: Text
- Ethical considerations: Potential for bias, harmful outputs, misuse
- Limitations: Lack of grounded reasoning, factually incorrect outputs

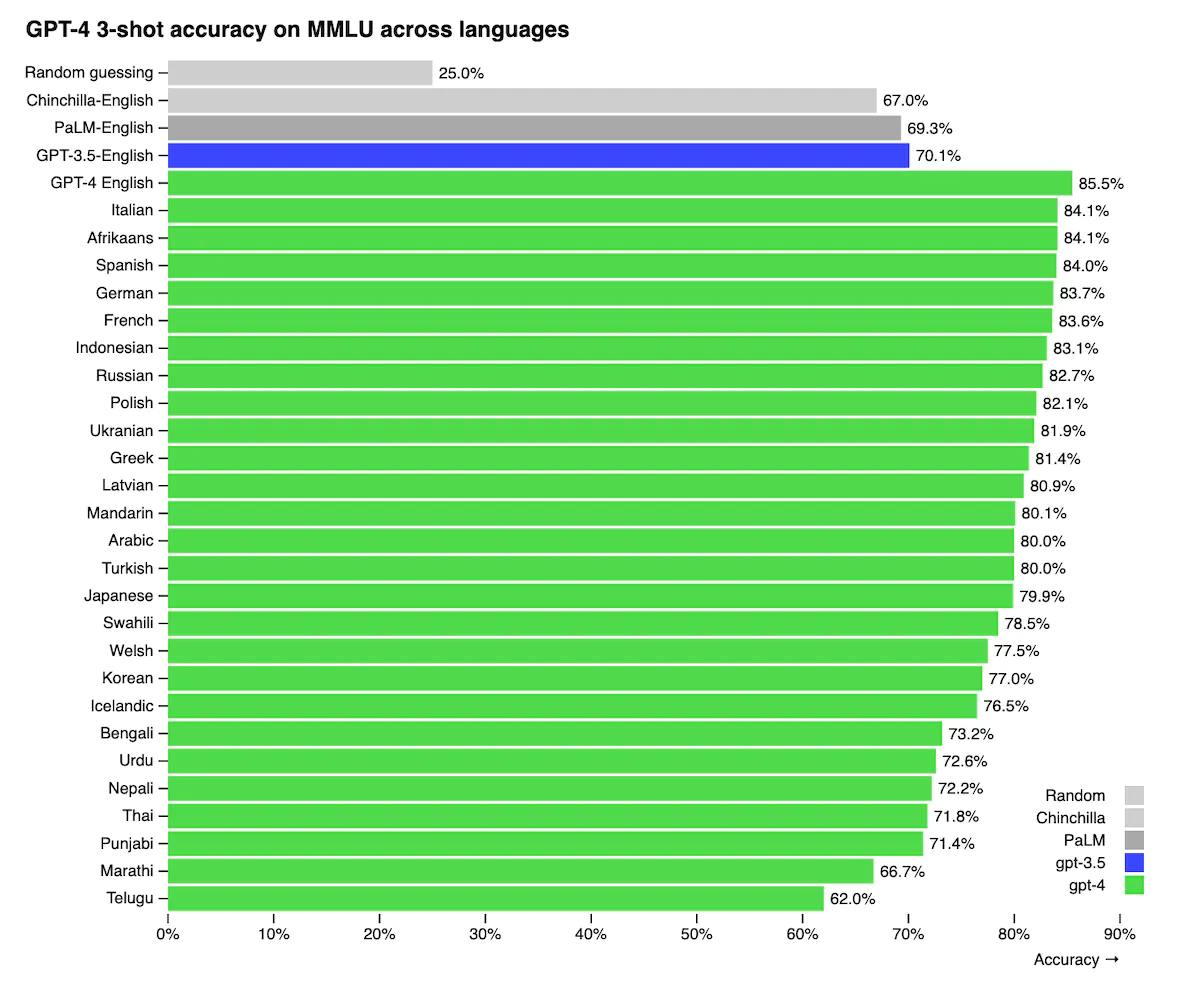
Model Architecture
GPT-4 utilizes a mixture of experts (MoE) architecture with separate expert neural networks that specialize in certain tasks or data types.
- 16 expert models, each with ~111B parameters
- 2 experts activated per inference query
- 55B shared parameters for attention
- ~280B parameters used per inference pass
This allows the overall model to scale up while keeping inference costs practical. The specialized experts can also develop unique capabilities.


Training Process
Training a 1.8 trillion parameter model required extensive computational resources:
- Trained on ~25,000 Nvidia A100 GPUs simultaneously
- 90-100 days of continuous training
- 13 trillion training tokens
- 2.15e25 floating point operations (FLOPs) total
Various parallelism techniques enabled this scale:
- 8-way tensor parallelism
- 15-way pipeline parallelism
- Clustering topologies to maximize inter-GPU bandwidth
Inference Serving
Deploying GPT-4 also requires specialized infrastructure:
- Runs on clusters of 128 A100 GPUs
- Leverages 8-way tensor and 16-way pipeline parallelism
- Carefully balances latency, throughput, and utilization
- Uses speculative decoding to improve throughput
Dense inference clusters keep query costs affordable at scale.
Token Dropping
The MoE routing mechanism can lead to token dropping, where some tokens are unprocessed due to expert capacity limits.
- Drops are non-deterministic based on batch token routing
- Some level of dropping is beneficial for efficiency
- Varying drops lead to observed randomness, but model logic is consistent
Future Directions
While impressive, GPT-4 remains focused on text. Future areas of research include:
- Architectures supporting vision, audio, speech
- Training across modalities
- Alternatives to MoE for scalability
- Expanding training data diversity and size
- Advancing multi-modal reasoning
- Optimizing for real-world performance
GPT-4 demonstrates the rapid pace of progress in language models. While we are still far from general intelligence, OpenAI continues pushing towards this goal with each new iteration. Exciting capabilities likely lie ahead.

L O A D I N G
. . . comments & more!
. . . comments & more!












