Unveiling Infinite Context Windows: Leveraging LLMs in Streaming Apps with Attention Sinks by@mikeyoung44

1,209 reads
Unveiling Infinite Context Windows: Leveraging LLMs in Streaming Apps with Attention Sinks
by Mike YoungOctober 4th, 2023





Too Long; Didn't Read
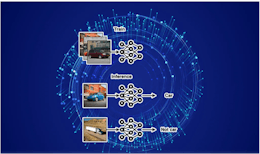
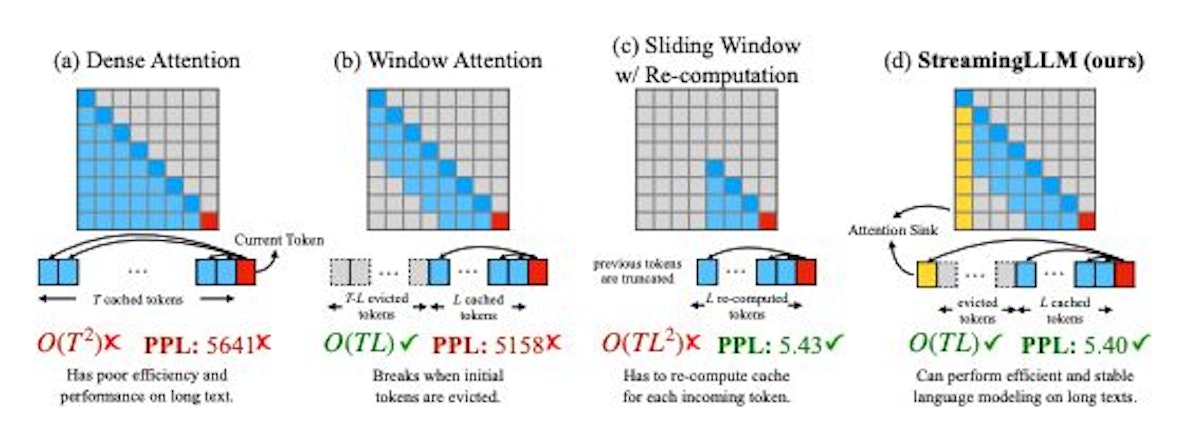
Researchers from MIT, Meta AI, and Carnegie Mellon recently proposed StreamingLLM, an efficient framework to enable infinite-length language modeling in LLMs. Their method cleverly exploits the LLMs' tendency to use initial tokens as "attention sinks" to anchor the distribution of attention scores. By caching initial tokens alongside recent ones, they achieved up to 22x faster decoding than prior techniques.


Mike Young
@mikeyoung44

L O A D I N G
. . . comments & more!
. . . comments & more!