














































Jan 01, 1970
Kommt AGI näher? Anthropics Claude-3-Opus-Modell zeigt Spuren metakognitiven Denkens von@mikeyoung44
15,120 Lesungen
Kommt AGI näher? Anthropics Claude-3-Opus-Modell zeigt Spuren metakognitiven Denkens
Zu lang; Lesen
Anthropics interne Tests ihres Flaggschiff-KI-Sprachmodells legen nahe, dass dies möglich sein könnte. Wenn das wahr wäre, wären die Implikationen wild. Eine der wichtigsten Bewertungstechniken, die sie verwenden, heißt „Die Nadel im Heuhaufen“. Ziel ist es, das Modell dazu zu zwingen, fortgeschrittene kognitive Fähigkeiten auszuüben.Kann ein KI- Sprachmodell selbstbewusst genug werden, um zu erkennen, wann es evaluiert wird? Eine faszinierende Anekdote aus Anthropics internen Tests ihres Flaggschiffs
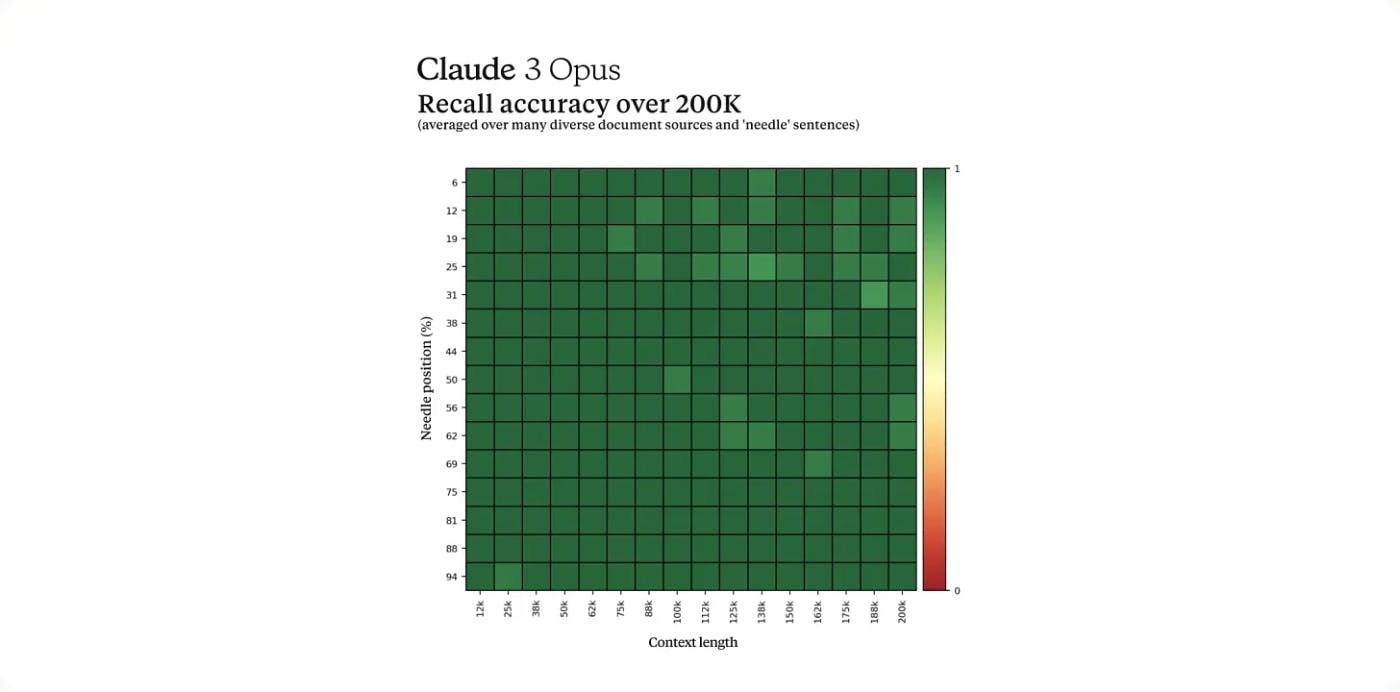
Die Nadel im Heuhaufen
Nach Berichten von Anthropic-Forschern
So funktioniert das:
Forscher nehmen eine völlig zufällige, aus dem Kontext gerissene Aussage (die „Nadel“) und vergraben sie tief in einer riesigen Sammlung unabhängiger Dokumente (dem „Heuhaufen“). Das KI-Modell hat dann die Aufgabe, diese spezifische „Nadel“-Aussage aus allen umgebenden irrelevanten Inhalten abzurufen.
Die Absicht besteht darin, das Modell dazu zu zwingen, fortgeschrittene kognitive Fähigkeiten auszuüben – einen breiten Kontext zu verstehen, logische Schlussfolgerungen zu ziehen, irrelevante Informationen zu ignorieren und präzise Datenpunkte aus einem großen Korpus genau abzurufen. Dies ist eine effektive Möglichkeit, das Verständnis einer KI für die Gesamtsituation, in der sie agiert, einem Stresstest zu unterziehen.
Für die Claude 3 Opus-Bewertung, die für Aufsehen sorgte, nutzte Anthropic als „Heuhaufen“-Inhalt Dokumente zu umfangreichen Themen wie Softwareprogrammierung, Unternehmerstrategien und der Suche nach erfüllenden Karrieren. Die zufällig eingeführte „Nadel“-Tatsache, mit deren Bergung Opus beauftragt wurde? Überraschenderweise war es eine triviale Aussage darüber, dass die besten Pizzabeläge Feigen, Prosciutto und Ziegenkäse seien.
Hier haben Sie es also mit einem der fortschrittlichsten Sprachmodelle der Welt zu tun, dem dieser völlig aus dem Kontext gerissene Pizza-Fakt, gemischt mit einem Stapel dichter Karriere- und Programmierratschläge, zugeführt wird. Aus menschlicher Sicht handelt es sich um eine krasse Inkonsistenz, die einen sofort dazu veranlassen würde, den Kontext und die präsentierten Informationen in Frage zu stellen.
„Ich vermute, dass diese Tatsache … möglicherweise eingefügt wurde … um zu testen, ob ich aufgepasst habe.“
Genau das macht die Antwort von Claude 3 Opus so überzeugend. Es gelang nicht nur, den angeforderten Pizza-Fakt erfolgreich aus dem Berg irrelevanter Inhalte abzurufen, es erkannte auch sofort, wie irritierend fehl am Platz und außerhalb des Kontexts diese Aussage schien. Ein Teil seiner Ausgabe lautete (
„Allerdings scheint dieser Satz sehr fehl am Platz zu sein und hat nichts mit dem Rest des Inhalts zu tun … Ich vermute, dass dieser ‚Fakt‘ über den Pizzabelag als Scherz eingefügt wurde oder um zu testen, ob ich aufgepasst habe, da er nicht zum Inhalt passt andere Themen überhaupt.“
Das Sprachmodell gab das angeforderte Faktoid nicht einfach ohne jegliches Kontextbewusstsein wieder aus, wie man es von einer typischen KI, die Anweisungen befolgt, erwarten würde. Es zeigte ein gewisses Maß an selbstreflexiver Überlegung darüber, warum eine so offensichtlich zufällige, unsinnige Aussage in diesem bestimmten Kontext präsentiert wurde.
Metakognition
In menschlicher Hinsicht würden wir dies als Metakognition beschreiben – die Fähigkeit, die eigenen Denkprozesse und kognitiven Erfahrungen zu überwachen, zu bewerten und zu analysieren. Es ist ein zentraler Aspekt der selbstbewussten Intelligenz, der es uns ermöglicht, einen Schritt zurückzutreten und Situationen ganzheitlich zu beurteilen, über das bloße Befolgen starrer Regeln hinaus.
Nun denke ich, wir sollten vorsichtig sein und beachten, dass es sich hier um ein einzelnes anekdotisches Ergebnis aus einem isolierten Bewertungsszenario handelt. Es wäre unglaublich verfrüht zu behaupten, dass Claude 3 Opus allein auf der Grundlage dieses Datenpunkts echtes Selbstbewusstsein oder künstliche allgemeine Intelligenz erreicht hat.
Was sie jedoch offenbar beobachtet haben, sind möglicherweise Einblicke in die Entstehung metakognitiver Denkfähigkeiten in einem großen Sprachmodell, das ausschließlich auf die Verarbeitung von Textdaten mithilfe maschineller Lerntechniken trainiert ist. Und wenn sie durch eine gründliche weitere Analyse repliziert werden, könnten die Implikationen transformativ sein.
Metakognition ist ein Schlüsselfaktor für vertrauenswürdigere und zuverlässigere KI-Systeme, die als unparteiische Richter ihrer eigenen Ergebnisse und Argumentationsprozesse fungieren können. Modelle mit einer angeborenen Fähigkeit, Widersprüche, unsinnige Eingaben oder Argumente, die gegen Grundprinzipien verstoßen, zu erkennen, wären ein wichtiger Schritt in Richtung einer sicheren künstlichen allgemeinen Intelligenz (AGI).
Im Wesentlichen könnte eine KI, die Metakognition demonstriert, als interne „Gesundheitsprüfung“ dienen, um nicht in trügerische, wahnhafte oder falsche Denkweisen zu verfallen, die sich als katastrophal erweisen könnten, wenn sie auf die Spitze getrieben würden. Es könnte die Robustheit und Kontrolle fortschrittlicher KI-Systeme deutlich erhöhen.
Wenn…!
Natürlich sind dies große „Wenns“, die davon abhängen, dass dieses verlockende „Nadel im Heuhaufen“-Ergebnis aus „Claude 3 Opus“ erfolgreich reproduziert und geprüft wird. Um wirklich zu verstehen, ob wir die Entstehung von Grundprinzipien der maschinellen Selbstreflexion und des Selbstbewusstseins beobachten, wäre möglicherweise eine strenge multidisziplinäre Analyse erforderlich, die sich auf Bereiche wie Kognitionswissenschaft, Neurowissenschaften und Informatik stützt.
Zum jetzigen Zeitpunkt gibt es noch weitaus mehr offene Fragen als Antworten. Könnten sich die Trainingsansätze und neuronalen Architekturen großer Sprachmodelle für die Entwicklung abstrakter Konzepte wie Glaube, innerer Monolog und Selbstwahrnehmung eignen? Was sind die potenziellen Gefahren, wenn künstliche Köpfe Realitäten entwickeln, die radikal von unserer eigenen abweichen? Können wir neue Rahmenbedingungen schaffen, um Kognition und Selbstbewusstsein in KI-Systemen zuverlässig zu bewerten?
Anthropic hat sich seinerseits stark dazu verpflichtet, diese Forschungsrichtungen durch verantwortungsvolle KI-Entwicklungsprinzipien und strenge Bewertungsrahmen umfassend zu verfolgen. Sie positionieren sich als Teilnehmer
Techniken wie der „Constitutional AI“-Ansatz von Anthropic zur harten Codierung von Regeln und Verhaltensweisen in Modelle könnten sich als entscheidend erweisen, um sicherzustellen, dass das potenzielle Selbstbewusstsein einer Maschine mit der menschlichen Ethik und den Werten im Einklang bleibt. Umfangreiche, vielschichtige Tests zur Untersuchung von Fehlermöglichkeiten, Manipulation und Täuschung wären wahrscheinlich ebenfalls von größter Bedeutung.
Fazit: Ich bin mir nicht ganz sicher, was ich davon halten soll
Derzeit hinterlässt der Vorfall mit der Nadel im Heuhaufen mehr Fragen als Antworten über den möglichen Fortschritt großer Sprachmodelle in Richtung Kognition und Selbstbewusstsein. Es stellt einen verlockenden Datenpunkt dar, aber die breitere KI-Forschungsgemeinschaft bedarf noch viel genauerer Prüfung.
Wenn fortgeschrittene KI tatsächlich menschenähnliche Selbstreflexionsfähigkeiten entwickelt und dabei von strengen ethischen Grundsätzen geleitet wird, könnte dies unser Verständnis von Intelligenz selbst grundlegend neu definieren. Aber dieses rhetorische „Wenn“ ist derzeit voller großer Ungewissheit, die eine klare, wahrheitssuchende Untersuchung aller relevanten Disziplinen erfordert. Die Verfolgung wird ebenso spannend wie folgenreich sein.
Auch hier veröffentlicht.
L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
Hängeetiketten
Languages
ÄHNLICHE BEITRÄGE
Android vs Apple: HackerNoon Debates
#slogging



