



























































Jan 01, 1970
7,838 讀數
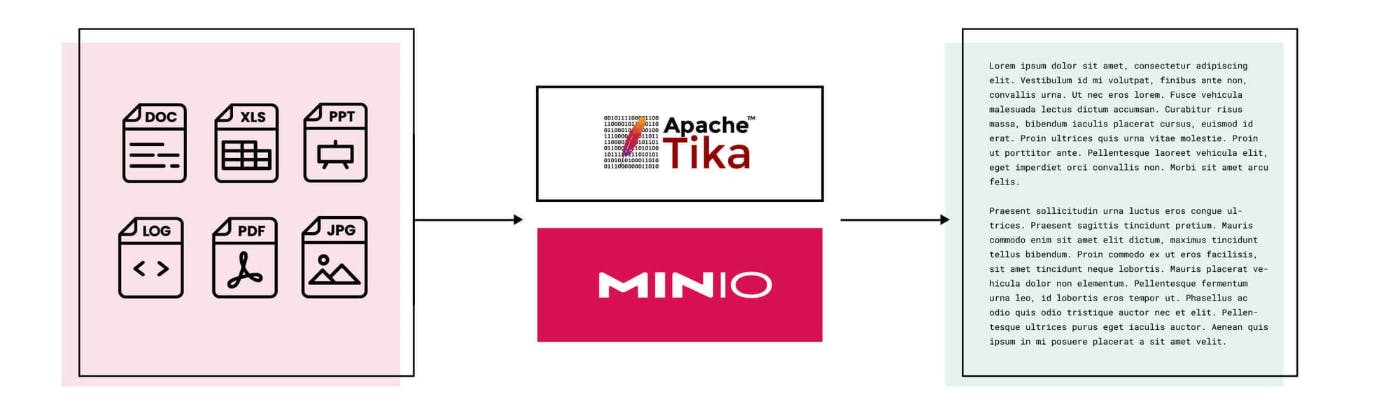
利用 MinIO 和 Apache Tika 进行自动文本提取和分析
太長; 讀書
在本文中,我们将使用 MinIO Bucket Notifications 和 Apache Tika 进行文档文本提取,这是大型语言模型 (LLM) 训练和检索增强生成 (RAG) 等关键下游任务的核心。
在本文中,我们将使用 MinIO Bucket Notifications 和 Apache Tika 进行文档文本提取,这是大型语言模型 ( LLM ) 训练和检索增强生成 ( RAG ) 等关键下游任务的核心。
前提
假设我想构建一个文本数据集,然后使用它来
设置 Apache Tika
启动并运行 Apache Tika 的最简单方法是使用
在这个例子中,我允许它使用并公开默认端口 9998。
docker pull apache/tika:<version> docker run -d -p 127.0.0.1:9998:9998 apache/tika:<version>
使用docker ps或 Docker Desktop 验证 Tika 容器正在运行并已公开端口 9998。
构建文本提取服务器
现在 Tika 已运行,我们需要构建一个服务器,该服务器可以以编程方式发出 Tika 新对象提取请求。接下来,我们需要在 MinIO 存储桶上配置 webhook,以提醒此服务器有新对象到达(换句话说,存储桶的 PUT 事件)。让我们一步一步地介绍一下。
为了使事情相对简单,并突出这种方法的可移植性,文本提取服务器将使用流行的 Flask 框架以 Python 构建。以下是服务器的代码(也可在 MinIO 博客资源存储库中找到
""" This is a simple Flask text extraction server that functions as a webhook service endpoint for PUT events in a MinIO bucket. Apache Tika is used to extract the text from the new objects. """ from flask import Flask, request, abort, make_response import io import logging from tika import parser from minio import Minio # Make sure the following are populated with your MinIO details # (Best practice is to use environment variables!) MINIO_ENDPOINT = '' MINIO_ACCESS_KEY = '' MINIO_SECRET_KEY = '' # This depends on how you are deploying Tika (and this server): TIKA_SERVER_URL = 'http://localhost:9998/tika' client = Minio( MINIO_ENDPOINT, access_key=MINIO_ACCESS_KEY, secret_key=MINIO_SECRET_KEY, ) logger = logging.getLogger(__name__) app = Flask(__name__) @app.route('/', methods=['POST']) async def text_extraction_webhook(): """ This endpoint will be called when a new object is placed in the bucket """ if request.method == 'POST': # Get the request event from the 'POST' call event = request.json bucket = event['Records'][0]['s3']['bucket']['name'] obj_name = event['Records'][0]['s3']['object']['key'] obj_response = client.get_object(bucket, obj_name) obj_bytes = obj_response.read() file_like = io.BytesIO(obj_bytes) parsed_file = parser.from_buffer(file_like.read(), serverEndpoint=TIKA_SERVER_URL) text = parsed_file["content"] metadata = parsed_file["metadata"] logger.info(text) result = { "text": text, "metadata": metadata } resp = make_response(result, 200) return resp else: abort(400) if __name__ == '__main__': app.run()
让我们启动提取服务器:
记下 Flask 应用程序正在运行的主机名和端口。
设置存储桶通知
现在,剩下的就是在 MinIO 服务器上为存储桶配置 webhook,以便存储桶中的任何 PUT 事件(即添加的新对象)都会触发对提取端点的调用。使用mc工具,我们只需几个命令即可完成此操作。
首先,我们需要设置一些环境变量,以向您的 MinIO 服务器发出信号,表明您正在启用 webhook 和要调用的相应端点。将 <YOURFUNCTIONNAME> 替换为您选择的函数名称。为简单起见,我选择了“extraction”。此外,请确保将端点环境变量设置为推理服务器的正确主机和端口。在本例中,http://localhost:5000 是我们的 Flask 应用程序运行的位置。
export MINIO_NOTIFY_WEBHOOK_ENABLE_<YOURFUNCTIONNAME>=on export MINIO_NOTIFY_WEBHOOK_ENDPOINT_<YOURFUNCTIONNAME>=http://localhost:5000
设置这些环境变量后,启动mc ,因此请确保您已经拥有它
接下来,让我们为我们的存储桶配置事件通知以及我们想要通知的事件类型。为了这个项目的目的,我创建了一个全新的存储桶,也称为“提取”。您可以这样做mc
mc event add ALIAS/BUCKET arn:minio:sqs::<YOURFUNCTIONNAME>:webhook --event put
最后,您可以通过验证运行此命令时是否输出s3:ObjectCreated:*来检查是否为存储桶通知配置了正确的事件类型:
mc event ls ALIAS/BUCKET arn:minio:sqs::<YOURFUNCTIONNAME>:webhook
如果您想了解有关将存储桶事件发布到 webhook 的更多信息,请查看
试试看
这是我想从中提取文本的文档。它是
我使用 MinIO 控制台将此 PDF 放入我的“提取”存储桶中。
此 PUT 事件触发存储桶通知,然后该通知将发布到提取服务器端点。因此,Tika 会提取文本并将其打印到控制台。
下一步
虽然我们现在只是打印出提取的文本,但这些文本可以用于许多下游任务,正如前提中所暗示的那样。例如:
为 LLM 微调创建数据集:假设您想要针对一系列以各种文件格式(即 PDF、DOCX、PPTX、Markdown 等)存在的公司文档来微调大型语言模型。要为此任务创建 LLM 友好的文本数据集,您可以将所有这些文档收集到配置了类似 webhook 的 MinIO 存储桶中,并将每个文档的提取文本传递到微调/训练集的数据框中。此外,通过将数据集的源文件放在 MinIO 上,管理、审计和跟踪数据集的组成变得更加容易。
检索增强生成:RAG 是 LLM 应用程序利用精确上下文并避免幻觉的一种方式。这种方法的核心是确保可以提取文档的文本,然后将其嵌入到向量中,从而实现语义搜索。此外,将这些向量的实际源文档存储在对象存储(如 MinIO!)中通常是最佳做法。使用本文概述的方法,您可以轻松实现这两个目标。如果您想了解有关 RAG 及其优势的更多信息,请查看此
早期帖子 。
LLM 应用:通过编程方式立即从新存储的文档中提取文本,可能性是无穷无尽的,特别是如果您可以利用 LLM。想想关键字检测(即提示:“提到了哪些股票代码?”)、内容评估(即提示:“根据评分标准,这篇论文应该得到多少分?”)或几乎任何类型的基于文本的分析(即提示:“根据此日志输出,第一个错误发生在什么时候?”)。
除了 Bucket Notifications 对于这些任务的实用性之外,MinIO 还可以为任何类型和数量的对象提供世界一流的容错能力和性能——无论它们是 Powerpoint、图像还是代码片段。
L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
標籤
Languages
这篇文章刊登在...
相關故事
加密交易中的网络安全:您需要知道的一切
#cybersecurity

庆祝战争机器人十周年并从技术角度进行反思 #game-development
Jan 01, 1970

关于如何在 JavaScript 增强表单中取消重复获取请求的指南 #web-development
Jan 01, 1970

