





164 reads
Practical Feedback on Using Machine Learning in Information Security
by Vijay MurganoorApril 29th, 2024





Too Long; Didn't Read
Bad actors create fake profiles that can be used to carry out many different types of abuse: scraping, spamming, fraud, and phishing. A funnel of defenses are built to detect and take down fake accounts at multiple stages. Organizations can further enhance their cybersecurity by incorporating the Completely Automated Public Turing test to tell Computers and Humans Apart.

Have you ever wondered about how X(formerly known as Twitter) identifies bots that are tweeting spam? or how banks identify fraudulent accounts? or how GitHub identifies faulty servers in the network?
Such systems are built by information security teams that monitor and take down such activities at scale using AI/ML systems. In cases where the automation can’t handle or identify, incident response teams take them down. These learnings are captured and then train new ML classifiers to identify outliers.
Bad actors have a wide range of sophistication and their intent varies too. Some bad actors create fake profiles that can be used to carry out many different types of abuse: scraping, spamming, fraud, and phishing, among others. To build robust countermeasures against different types of attacks on our platform, a funnel of defenses is built to detect and take down fake accounts at multiple stages.
Example of how an attacker goes after your system
(1) The attacker needs to first create an account for which they would use PVAcreator or other tools


(2) Using the automated accounts, the attacker needs to reach the data by navigating through the network and moving laterally.

(3) Once the attacker has access to the data, the attacker needs to exfiltrate this data out of the network.

Some strategies to start employing before using ML approach
- IP-Based Rate Limiting
-
Limits the number of requests from a single IP address within a specific timeframe.
-
Helps mitigate DDoS attacks and brute-force attempts.
-
- User-Based Rate Limiting
-
Sets a cap on the requests a single user can make within a given time window.
-
Guards against abuse and unauthorized access attempts.
-
- Token-Based Rate Limiting
-
Uses unique tokens or API keys to track and control API requests per token.
-
Secures APIs from misuse and potential data leaks.
-
- Using CAPTHA to distinguish between automated bots and legitimate human users
- In addition to the traditional rate limiting techniques mentioned above, organizations can further enhance their cybersecurity by incorporating the Completely Automated Public Turing test to tell Computers and Humans Apart (CAPTCHA) challenges.
Very soon you will start seeing these rules become quite ineffective as attackers rotate IPs, accounts, and tokens. They will start slowing down requests e.t.c
Bird's-Eye View of Information Security Framework


Building ML/AI-based solution
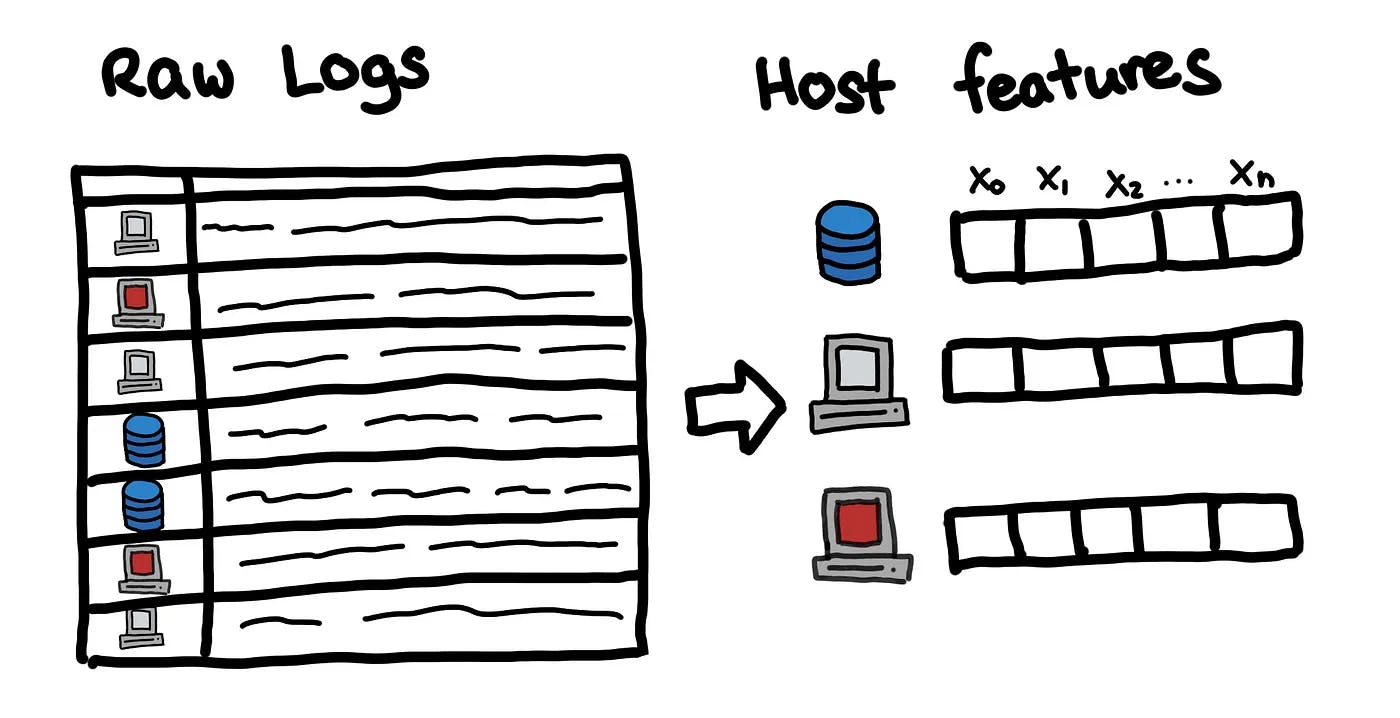
You need to start collecting logs and turn them into ML features for training.
Here is an example of building features based on the traffic data you see:

Here are some examples of features this paper has developed from logs:
- RDP Features: SuccessfulLogonRDPPortCount, UnsuccessfulLogonRDPPortCount, RDPOutboundSuccessfulCount, RDPOutboundFailedCount, RDPInboundCount
- SQL Features: UnsuccessfulLogonSQLPortCount, SQLOutboundSuccessfulCount, SQLOutboundFailedCount, SQLInboundCount
- Successful Logon Features: SuccessfulLogonTypeInteractiveCount, SuccessfulLogonTypeNetworkCount, SuccessfulLogonTypeUnlockCount, SuccessfulLogonTypeRemoteInteractiveCount, SuccessfulLogonTypeOtherCount
- Unsuccessful Logon Features: UnsuccessfulLogonTypeInteractiveCount, UnsuccessfulLogonTypeNetworkCount, UnsuccessfulLogonTypeUnlockCount, UnsuccessfulLogonTypeRemoteInteractiveCount, UnsuccessfulLogonTypeOtherCount
- Others: NtlmCount, DistinctSourceIPCount, DistinctDestinationIPCount
With such feature vectors, we can build a matrix and start using outlier detection techniques.


- Principal Component Analysis (PCA): We start with a classical way of finding outliers using PCA because it is the most visual, in my opinion. In simple terms, you can think of PCA is a way to compress and decompress data, where the data lost during compression in minimized. Here is an example from fast.ai
2. Auto-encoders: These are in short non-linear version of PCA.


The neural network is constructed such that there is an information bottleneck in the middle. By forcing the network to go through a small number of nodes in the middle, it forces the network to prioritize the most meaningful latent variables, which is like the principal components in PCA. Here is an example using fast.ai


- Isolation Forest and other decision forest: Anomalies have two characteristics. They are distanced from normal points and there are only a few of them. Isolation Forest randomly cuts a given sample until a point is isolated. The intuition is that outliers are relatively easy to isolate. Isolation Forest is a tree ensemble method of detecting anomalies was first proposed by
Liu, Ting, and Zhou . Here is an example from scikits.

L O A D I N G
. . . comments & more!
. . . comments & more!












